This article is based on Spring Data Redis 2.4.9
We had another production incident recently! A new microservice system just went live, and right after deployment, we started getting timeout errors for all requests sent to this system. What’s going on here?
Troubleshooting Approach#
Once again, we turned to our trusty JFR for investigation (you can check out my other series articles where JFR frequently saves the day). For historical slow request responses, I typically follow this diagnostic flow:
- Check for STW (Stop-the-world):
- Any long STW caused by GC?
- Any other reasons causing all process threads to enter safepoint, triggering STW?
- Is I/O taking too long? Like calls to other microservices, accessing various storage systems (disk, database, cache, etc.)
- Are threads blocked too long on certain locks?
- Is CPU usage too high? Which threads are causing it?
Through JFR analysis, we discovered that many HTTP threads were blocked on a single lock - the lock for acquiring connections from the Redis connection pool. Our project uses spring-data-redis with lettuce as the underlying client. Why would it block here? After investigation, I found that spring-data-redis has a connection leak issue.
Spring Data Redis Lettuce Deep Dive#
Let’s start with a quick introduction to Lettuce. Simply put, Lettuce is a non-blocking reactive Redis client implemented using Project Reactor + Netty. Spring-data-redis provides unified encapsulation for Redis operations. Our project uses the spring-data-redis + Lettuce combination.
To help everyone understand the root cause, let me first briefly explain the spring-data-redis + lettuce API structure.
First, the official Lettuce team doesn’t recommend using connection pools, but they don’t explain under what circumstances this decision applies. Here’s the conclusion upfront:
- If your project uses spring-data-redis + lettuce with only simple Redis commands (no Redis transactions, pipelines, etc.), then not using a connection pool is optimal (assuming you haven’t disabled Lettuce connection sharing, which is enabled by default).
- If your project heavily uses Redis transactions, then using a connection pool is recommended
- More precisely, if you frequently use commands that trigger
execute(SessionCallback), connection pools are recommended. If you mainly useexecute(RedisCallback)commands, connection pools aren’t necessary. For heavy pipeline usage, connection pools are still recommended.
Now let’s dive into the spring-data-redis API principles. In our project, we mainly use two core APIs from spring-data-redis: the synchronous RedisTemplate and asynchronous ReactiveRedisTemplate. We’ll focus on the synchronous RedisTemplate as our example. ReactiveRedisTemplate is essentially an async wrapper - since Lettuce is inherently asynchronous, ReactiveRedisTemplate is actually simpler to implement.
All Redis operations in RedisTemplate are ultimately wrapped into two types of operation objects. First is RedisCallback<T>:
public interface RedisCallback<T> {
@Nullable
T doInRedis(RedisConnection connection) throws DataAccessException;
}
This is a Functional Interface with RedisConnection as input parameter, allowing Redis operations through RedisConnection. It can contain multiple Redis operations. Most simple Redis operations in RedisTemplate are implemented this way. For example, the Get request source code implementation:
//Adds unified deserialization operations on top of RedisCallback
abstract class ValueDeserializingRedisCallback implements RedisCallback<V> {
private Object key;
public ValueDeserializingRedisCallback(Object key) {
this.key = key;
}
public final V doInRedis(RedisConnection connection) {
byte[] result = inRedis(rawKey(key), connection);
return deserializeValue(result);
}
@Nullable
protected abstract byte[] inRedis(byte[] rawKey, RedisConnection connection);
}
//Redis Get command implementation
public V get(Object key) {
return execute(new ValueDeserializingRedisCallback(key) {
@Override
protected byte[] inRedis(byte[] rawKey, RedisConnection connection) {
//Execute get command using connection
return connection.get(rawKey);
}
}, true);
}
The other type is SessionCallback<T>:
public interface SessionCallback<T> {
@Nullable
<K, V> T execute(RedisOperations<K, V> operations) throws DataAccessException;
}
SessionCallback is also a Functional Interface that can contain multiple commands in its method body. As the name suggests, all commands within this method share the same session - using the same Redis connection that cannot be shared. This is typically used for Redis transactions.
The main APIs in RedisTemplate are these few methods, with all commands implemented using these underlying APIs:
execute(RedisCallback<?> action)andexecutePipelined(final SessionCallback<?> session): Execute a series of Redis commands, serving as the foundation for all methods. Connection resources are automatically released after execution.executePipelined(RedisCallback<?> action)andexecutePipelined(final SessionCallback<?> session): Execute a series of commands using Pipeline. Connection resources are automatically released after execution.executeWithStickyConnection(RedisCallback<T> callback): Execute a series of Redis commands. Connection resources are NOT automatically released. Various Scan commands are implemented through this method because Scan commands return a Cursor that needs to maintain the connection (session), leaving it to the user to decide when to close.
Connection Acquisition Mechanism#
Through source code analysis, we can see that the three APIs in RedisTemplate often involve nested recursive calls in practical applications.
For example, cases like this:
redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
orders.forEach(order -> {
connection.hashCommands().hSet(orderKey.getBytes(), order.getId().getBytes(), JSON.toJSONBytes(order));
});
return null;
}
});
and
redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
orders.forEach(order -> {
redisTemplate.opsForHash().put(orderKey, order.getId(), JSON.toJSONString(order));
});
return null;
}
});
are equivalent. redisTemplate.opsForHash().put() actually calls the execute(RedisCallback) method, creating a nested scenario of executePipelined with execute(RedisCallback). This allows us to compose various complex situations, but how are the connections maintained internally?
These methods all use the RedisConnectionUtils.doGetConnection method to acquire connections and execute commands. For the Lettuce client, this returns an org.springframework.data.redis.connection.lettuce.LettuceConnection. This connection wrapper contains two actual Lettuce Redis connections:
private final @Nullable StatefulConnection<byte[], byte[]> asyncSharedConn;
private @Nullable StatefulConnection<byte[], byte[]> asyncDedicatedConn;
- asyncSharedConn: Can be null. If connection sharing is enabled (default), this is not null. This is a Redis connection shared by all LettuceConnections - essentially the same connection for each LettuceConnection. Used for executing simple commands. Due to Netty client and Redis single-threaded processing characteristics, sharing one connection is still very fast. If connection sharing is disabled, this field is null and asyncDedicatedConn is used for commands.
- asyncDedicatedConn: Private connection. If session maintenance, transaction execution, pipeline commands, or fixed connections are needed, this asyncDedicatedConn must be used for Redis command execution.
Let’s look at the execution flow through a simple example. First, a simple command: redisTemplate.opsForValue().get("test"). Based on our previous source code analysis, we know this is essentially execute(RedisCallback) underneath. The flow is:
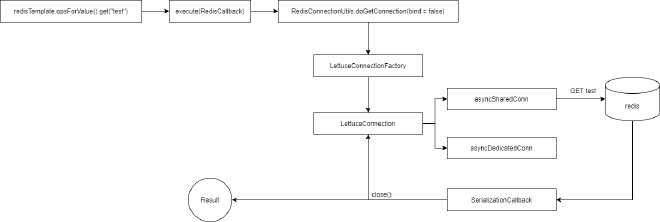
As we can see, if using RedisCallback, no connection binding is needed and no transactions are involved. The Redis connection is returned within the callback. Note that when calling executePipelined(RedisCallback), you must use the callback’s connection for Redis calls, not directly use redisTemplate calls, otherwise pipeline won’t take effect:
Pipeline effective:
List<Object> objects = redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
connection.get("test".getBytes());
connection.get("test2".getBytes());
return null;
}
});
Pipeline ineffective:
List<Object> objects = redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
redisTemplate.opsForValue().get("test");
redisTemplate.opsForValue().get("test2");
return null;
}
});
Next, let’s try adding it to a transaction. Since our goal isn’t actually testing transactions but demonstrating the issue, we’ll simply wrap the GET command with SessionCallback:
redisTemplate.execute(new SessionCallback<Object>() {
@Override
public <K, V> Object execute(RedisOperations<K, V> operations) throws DataAccessException {
return operations.opsForValue().get("test");
}
});
The biggest difference here is that when the outer layer acquires the connection, this time bind = true, meaning the connection is bound to the current thread to maintain session connection. The outer flow is:

The inner SessionCallback is essentially redisTemplate.opsForValue().get("test"), using the shared connection, not the dedicated connection, because we haven’t started a transaction yet (i.e., executed the multi command). If a transaction were started, the dedicated connection would be used. The flow is:
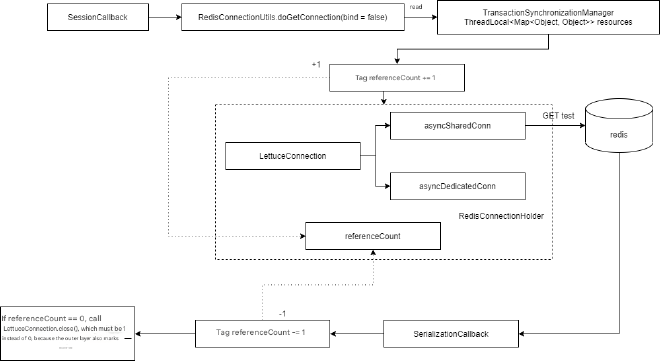
Since SessionCallback needs to maintain connections, the flow changes significantly. First, connection binding is required - essentially getting the connection and placing it in ThreadLocal. Additionally, the LettuceConnection is wrapped with a reference counting variable. Each nested execute increments this count by 1, and after execution, it decrements by 1. Each time execute ends, it checks this reference count, and if the reference count reaches zero, it calls LettuceConnection.close().
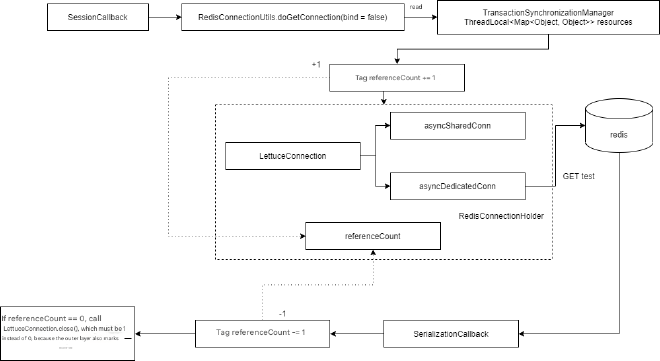
Now let’s see what happens with executePipelined(SessionCallback):
List<Object> objects = redisTemplate.executePipelined(new SessionCallback<Object>() {
@Override
public <K, V> Object execute(RedisOperations<K, V> operations) throws DataAccessException {
operations.opsForValue().get("test");
return null;
}
});
The main difference from the second example in terms of flow is that the connection used is not the shared connection, but directly the dedicated connection.
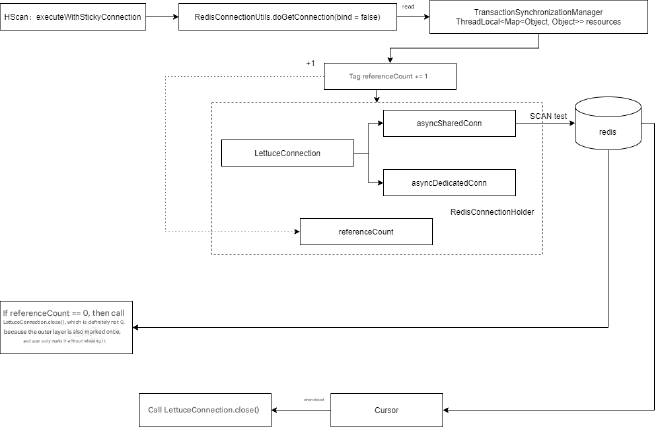
Finally, let’s look at an example of executing commands based on executeWithStickyConnection(RedisCallback<T> callback) within execute(RedisCallback). Various SCAN operations are based on executeWithStickyConnection(RedisCallback<T> callback), for example:
redisTemplate.execute(new SessionCallback<Object>() {
@Override
public <K, V> Object execute(RedisOperations<K, V> operations) throws DataAccessException {
Cursor<Map.Entry<Object, Object>> scan = operations.opsForHash().scan((K) "key".getBytes(), ScanOptions.scanOptions().match("*").count(1000).build());
//scan must be closed, using try-with-resource here
try (scan) {
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
});
The Session callback flow is shown below. Because it’s within SessionCallback, executeWithStickyConnection detects that a connection is currently bound, so it increments the marker by 1, but doesn’t decrement by 1, because executeWithStickyConnection can expose resources externally (like the Cursor here), requiring manual external closure.
Root Cause of Connection Leak#
In this example, connection leakage occurs. First, execute:
redisTemplate.execute(new SessionCallback<Object>() {
@Override
public <K, V> Object execute(RedisOperations<K, V> operations) throws DataAccessException {
Cursor<Map.Entry<Object, Object>> scan = operations.opsForHash().scan((K) "key".getBytes(), ScanOptions.scanOptions().match("*").count(1000).build());
//scan must be closed, using try-with-resource here
try (scan) {
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
});
This way, LettuceConnection gets bound to the current thread, and at the end, the reference count is not zero, but 1. When the cursor closes, it calls LettuceConnection’s close method. However, LettuceConnection’s close implementation only marks the state and closes the dedicated connection asyncDedicatedConn. Since no dedicated connection is currently used, it’s null and doesn’t need closing, as shown in the source code below:
@Override
public void close() throws DataAccessException {
super.close();
if (isClosed) {
return;
}
isClosed = true;
if (asyncDedicatedConn != null) {
try {
if (customizedDatabaseIndex()) {
potentiallySelectDatabase(defaultDbIndex);
}
connectionProvider.release(asyncDedicatedConn);
} catch (RuntimeException ex) {
throw convertLettuceAccessException(ex);
}
}
if (subscription != null) {
if (subscription.isAlive()) {
subscription.doClose();
}
subscription = null;
}
this.dbIndex = defaultDbIndex;
}
Then we continue executing a Pipeline command:
List<Object> objects = redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
connection.get("test".getBytes());
redisTemplate.opsForValue().get("test");
return null;
}
});
At this point, since the connection is already bound to the current thread, and as analyzed in the previous section, the first step should release this binding, but LettuceConnection’s close was called. Executing this code creates a dedicated connection, and because the count cannot reach zero, the connection remains bound to the current thread. Thus, this dedicated connection never closes (if there’s a connection pool, it never returns to the pool).
Even if we manually close this connection later, according to the source code, since the isClosed state is already true, the dedicated connection still cannot be closed. This causes connection leakage.
I’ve already submitted an issue to spring-data-redis regarding this bug: Lettuce Connection Leak while using execute(SessionCallback) and executeWithStickyConnection in same thread by random turn
Solutions#
- Avoid using
SessionCallbackas much as possible; only useSessionCallbackwhen Redis transactions are actually needed. - Encapsulate functions using
SessionCallbackseparately, keep transaction-related commands together, and avoid nesting additionalRedisTemplateexecuterelated functions in the outer layer.