I believe many Java developers have used various concurrency synchronization mechanisms in Java, such as volatile, synchronized, and Lock. Many have also read Chapter 17 “Threads and Locks” from the JSR specification (available at: https://docs.oracle.com/javase/specs/jls/se17/html/jls-17.html), which provides extensive specifications on synchronization, Wait/Notify, Sleep & Yield, and memory models. However, I believe most people, like myself, felt like they were just watching the show when reading it for the first time. After reading, we only knew what was specified, but didn’t have a clear understanding of why these rules existed or what would happen without them. Moreover, when combined with HotSpot implementation and source code analysis targeting HotSpot, we might even discover that due to javac’s static code compilation optimizations and C1/C2 JIT compilation optimizations, the final code behavior might be inconsistent with what we understand from the specification. This inconsistency can mislead us when learning the Java Memory Model (JMM), causing our potentially correct understanding to be skewed, leading to misconceptions.
I’ve been continuously trying to understand the Java Memory Model, re-reading JLS and analyses by various experts. This series will organize my personal understanding gained from reading these specifications, analyses, and experiments conducted with jcstress. I hope this will help everyone understand the Java Memory Model and API abstractions after Java 9. However, I must emphasize that memory model design aims to abstract away underlying details so developers don’t need to worry about them. Since this involves many complex concepts and my understanding may be limited, I’ll try to present all arguments with evidence and references. Please don’t blindly trust all viewpoints here. If you have any disagreements, please feel free to provide specific examples and leave comments.
1. Understanding “Specification” vs “Implementation”#
First, I’d like to reference the understanding approach from Aleksey Shipilëv, which is to distinguish between Specification and Implementation. The JLS (Java Language Specification) mentioned earlier is actually a specification that defines the Java language, and all JDK implementations capable of compiling and running Java must implement the functionality specified within it. However, actual implementations, such as HotSpot JVM’s JDK, are concrete implementations, and there are certain differences between specifications and actual implementations. Consider this code:
private int test() {
int x = 1;
int y = 2;
int result = x + y;
return result;
}
The actual code that HotSpot compiles and runs after JIT optimization and CPU instruction optimization is:
mov $3, %rax
ret
This puts the result 3 into a register and returns it, which has the same effect as the original code but eliminates unnecessary local variable operations, which is reasonable. You might wonder: “But when I set a breakpoint and run to this point, I can see local variables x, y, result!” This is actually work done by the JVM runtime. If you run the JVM in DEBUG mode, JIT is disabled by default and only simple interpretation execution occurs, so you can see local variables. But in actual execution, if this method is a hotspot method optimized by JIT, these local variables don’t actually exist.
Another example is HotSpot’s lock coarsening mechanism (which we’ll test later):
int x, y;
private void test() {
synchronized(this) {
x = 1;
}
synchronized(this) {
y = 1;
}
}
According to JLS description, the operations x = 1 and y = 1 cannot be reordered. However, HotSpot’s actual implementation will optimize the above code to:
int x, y;
private void test() {
synchronized(this) {
x = 1;
y = 1;
}
}
This way, the operations x = 1 and y = 1 can actually be reordered, which we’ll verify later.
Different JVM implementations will have different actual behaviors. Even the same JVM implementation may behave differently on different operating systems and hardware environments. For example:
long v;
Thread 1 executes:
v = 0xFFFFFFFF_FFFFFFFFL;
Thread 2 executes:
long r1 = v;
Normally, r1 should only have results from {-1, 0}. But on some 32-bit JVMs, there might be issues. For example, on x86_32 environments, you might get results like {-1, 0, -4294967296, 4294967295}.
So, if we were to comprehensively cover everything from underlying details to JMM design, HotSpot implementation, JIT optimization, etc., there would be too many layers of logic. I really can’t cover everything comprehensively, and I can’t guarantee 100% accuracy in my understanding. If we involve too much HotSpot implementation, we might deviate from our series’ main theme. What we mainly care about is the design specification of Java’s memory model itself, and then summarize the minimal set of points we need to know and pay attention to in actual use. This is what this series aims to organize. To ensure the accuracy of this minimal set, we’ll include many actual test codes that everyone can run to see if the conclusions and understanding of JMM presented here are correct.
2. What is a Memory Model#
Any language that needs to access memory requires a memory model to describe how to access memory: what methods can be used to write to memory, what methods can be used to read from memory, and what different behaviors different writing and reading methods will have. Of course, if your program is a simple serial program, what you read will definitely be the most recently written value. In such cases, you don’t really need something like a memory model. Memory models are generally needed in concurrent environments.
The Java Memory Model actually specifies what reasonable values can be observed in memory when reading or writing memory in different specific ways in a Java multi-threaded environment.
Some define Java memory as: Java instructions can be reordered, and the Java Memory Model specifies which instructions are prohibited from being reordered. This is actually the main content of the Java Memory Model in Chapter 17 of JLS. This is actually a way to achieve observing reasonable values in memory, i.e., for given source code, what the possible result set is.
Let’s look at two simple introductory examples as warm-up exercises: atomic access and word tearing.
3. Atomic Access#
Atomic access means that writing to and reading from a field is atomic and indivisible. A point that people might not often pay attention to is that according to Chapter 17 of JLS, the following two operations are not atomic access:
double a;
long b;
public void test() {
a = 1.2d;
}
Since most current systems are 64-bit, these two operations are mostly atomic. But according to Java specifications, these two are not atomic and cannot guarantee atomicity on 32-bit systems. I’ll directly quote a passage from Chapter 17 of JLS:
For the purposes of the Java programming language memory model, a single write to a non-volatile long or double value is treated as two separate writes: one to each 32-bit half. This can result in a situation where a thread sees the first 32 bits of a 64-bit value from one write, and the second 32 bits from another write. Writes and reads of volatile long and double values are always atomic.
Simply put, non-volatile long or double might be updated as two separate 32-bit writes, so they’re non-atomic. Volatile long and double reads and writes are always atomic.
To illustrate atomicity, I’ll reference an example from jcstress:
@JCStressTest
//If result r1 is 0, it's ACCEPTABLE, description: Seeing the default value: writer had not acted yet.
@Outcome(id = "0", expect = ACCEPTABLE, desc = "Seeing the default value: writer had not acted yet.")
//If result r1 is -1, it's ACCEPTABLE, description: Seeing the full value.
@Outcome(id = "-1", expect = ACCEPTABLE, desc = "Seeing the full value.")
//If result r1 is other values, it's ACCEPTABLE_INTERESTING, description: Other cases are violating access atomicity, but allowed under JLS.
@Outcome( expect = ACCEPTABLE_INTERESTING, desc = "Other cases are violating access atomicity, but allowed under JLS.")
@State
public static class Longs {
long v;
//One thread executes this method
@Actor
public void writer() {
v = 0xFFFFFFFF_FFFFFFFFL;
}
//Another thread executes this method
@Actor
public void reader(J_Result r) {
r.r1 = v;
}
}
Running this code with Java 8 32bit JVM (Java 9+ no longer supports 32-bit machines), the result is:
RESULT SAMPLES FREQ EXPECT DESCRIPTION
-1 8,818,463,884 70.12% Acceptable Seeing the full value.
-4294967296 9,586,556 0.08% Interesting Other cases are violating access atomicity, but allowed u...
0 3,747,652,022 29.80% Acceptable Seeing the default value: writer had not acted yet.
4294967295 86,082 <0.01% Interesting Other cases are violating access atomicity, but allowed u...
As you can see, the results include not only -1 and 0 (values specified in our code), but also some intermediate results.
4. Word Tearing#
Word tearing means updating one field or array element affects the value of another field or array element. For example, if a processor doesn’t provide functionality to write a single byte and the minimum granularity is int, updating a byte array on such a processor by simply reading the entire int containing the byte, updating the corresponding byte, and writing the entire int back would be problematic. Java has no word tearing phenomenon - fields and array elements are independent, and updating one field or element cannot affect reading and updating of any other fields or elements.
To illustrate word tearing, here’s a somewhat inappropriate example using thread-unsafe BitSet. BitSet’s abstraction is a bit set (individual 0s and 1s, which can be understood as a boolean collection). The underlying implementation is a long array, where one long stores 64 bits. Each update reads the long, updates the corresponding bit through bit operations, and writes it back. At the interface level, it’s updated bit by bit, but underneath it’s updated by long granularity (because it’s an underlying long array). Obviously, without synchronization locks, concurrent access would cause concurrency safety issues and word tearing:
@JCStressTest
//Result true true is ACCEPTABLE, representing no word tearing
@Outcome(id = "true, true", expect = ACCEPTABLE, desc = "Seeing both updates intact.")
//Result false true represents word tearing, because the result should be true true
@Outcome(id = "false, true", expect = ACCEPTABLE_INTERESTING, desc = "Destroyed one update.")
//Result true false represents word tearing, because the result should be true true
@Outcome(id = "true, false", expect = ACCEPTABLE_INTERESTING, desc = "Destroyed one update.")
@State
public static class BitSets {
BitSet bs = new BitSet();
//One thread executes this method
@Actor
public void writer1() {
bs.set(0);
}
//Another thread executes this method
@Actor
public void writer2() {
bs.set(1);
}
//After both threads finish and memory is visible, execute this method
@Arbiter
public void arbiter(ZZ_Result r) {
r.r1 = bs.get(0);
r.r2 = bs.get(1);
}
}
The result is:
RESULT SAMPLES FREQ EXPECT DESCRIPTION
false, true 31,106,818 2.41% Interesting Destroyed one update.
true, false 31,794,680 2.46% Interesting Destroyed one update.
true, true 1,226,998,534 95.12% Acceptable Seeing both updates intact.
This is a somewhat inappropriate example to illustrate word tearing. Java can guarantee no word tearing. For the BitSet example above, if we try to update a boolean array, the result would only be true true:
@JCStressTest
@Outcome(id = "true, true", expect = ACCEPTABLE, desc = "Seeing both updates intact.")
@Outcome( expect = FORBIDDEN, desc = "Other cases are forbidden.")
@State
public static class JavaArrays {
boolean[] bs = new boolean[2];
@Actor
public void writer1() {
bs[0] = true;
}
@Actor
public void writer2() {
bs[1] = true;
}
@Arbiter
public void arbiter(ZZ_Result r) {
r.r1 = bs[0];
r.r2 = bs[1];
}
}
This result would only be true true.
Next, we’ll enter a somewhat challenging section - memory barriers. However, don’t worry too much. From my personal experience, memory barriers are difficult to understand because most online resources don’t explain them from the underlying details that Java has already abstracted away for you. Direct understanding can be very hard to convince yourself, leading to guessing and misconceptions. So this article won’t immediately throw Doug Lea’s abstract and still-used four Java memory barriers at you (LoadLoad, StoreStore, LoadStore, and StoreLoad - as we’ll see later, these four memory barrier designs are somewhat outdated for modern CPUs, which now use acquire, release, and fence more). I hope to extract concepts that are easier to understand from articles and papers I’ve read about underlying details for your reference, making memory barriers easier to understand.
5. Memory Barriers#
5.1. Why Memory Barriers are Needed#
Memory Barrier (also called Memory Fence, or simply membar in some materials) is mainly used to solve problems where instruction reordering causes results inconsistent with expectations. Memory barriers prevent instruction reordering by adding memory barriers.
Why does instruction reordering occur? Mainly due to CPU reordering (including CPU memory reordering and CPU instruction reordering) and compiler reordering. Memory barriers can prevent these reorderings. If memory barriers work for both compilers and CPUs, they’re generally called hardware memory barriers. If they only work for compilers, they’re generally called software memory barriers. We’ll mainly focus on CPU-caused reordering, with a brief introduction to compiler reordering at the end.
5.2. CPU Memory Reordering#
We’ll start from CPU cache and cache coherence protocols to analyze why CPU reordering occurs. We’ll assume a simplified CPU model here. Please remember that actual CPUs are much more complex than the simplified CPU model presented here.
5.2.1. Simplified CPU Model - CPU Cache Starting Point - Reducing CPU Stall#
We’ll see that many designs in modern CPUs start from reducing CPU Stall. What is CPU Stall? Here’s a simple example: suppose the CPU needs to directly read data from memory (ignoring other structures like CPU cache, buses, and bus events):
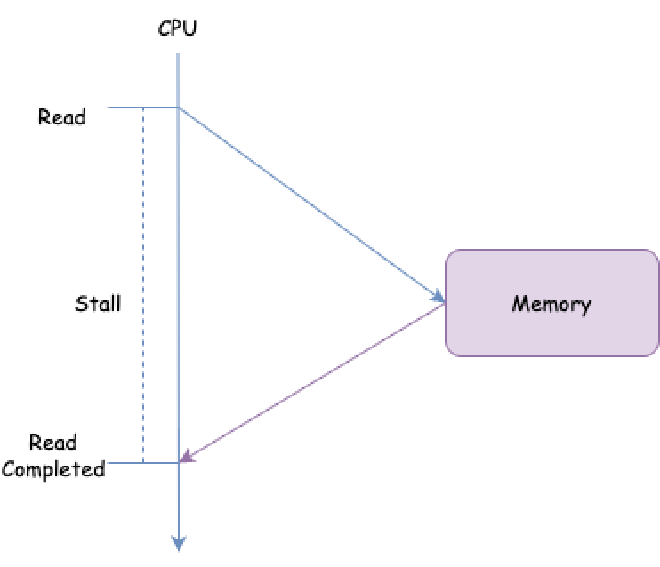
The CPU sends a read request and must wait until memory responds, unable to process other things. During this period, the CPU is in Stall state. If the CPU always reads directly from memory, direct CPU memory access takes a very long time, possibly requiring hundreds of instruction cycles. This means each access would have hundreds of instruction cycles where the CPU is in Stall state doing nothing, which is very inefficient. Generally, several levels of cache need to be introduced to reduce Stall: cache is small storage located close to the processor, between the processor and memory.
We don’t care about multi-level caches or whether multiple CPUs share certain caches. We’ll simply assume this architecture:

When reading a value from an address, the cache is accessed to see if it exists: existence represents a hit, and the value is read directly. Non-existence is called a miss. Similarly, if writing a value to an address and that address exists in cache, memory access isn’t needed. Most programs exhibit high locality:
- If a processor reads or writes a memory address, it will likely read or write the same address again soon.
- If a processor reads or writes a memory address, it will likely read or write nearby addresses soon.
For locality, caches generally operate on more than one word at a time, but rather a group of adjacent words, called cache lines.
However, due to cache existence, updating memory becomes troublesome: when one CPU needs to update memory corresponding to a cache line, it needs to invalidate that cache line in other CPUs’ caches. To maintain cache data consistency across CPUs, cache coherence protocols were introduced.
5.2.2. Simplified CPU Model - A Simple Cache Coherence Protocol (Actual CPUs Use More Complex Ones) - MESI#
Modern cache coherence protocols and algorithms are very complex, with cache lines potentially having dozens of different states. We don’t need to study such complex algorithms here. We’ll introduce the most classic and simple cache coherence protocol: the 4-state MESI protocol (Again emphasizing, actual CPUs use much more complex protocols than this. MESI itself has problems it cannot solve). MESI refers to four cache line states:
- Modified: Cache line is modified and will definitely be written back to main memory. Other processors cannot cache this cache line before that.
- Exclusive: Cache line hasn’t been modified, but other processors cannot load this cache line into cache.
- Shared: Cache line is unmodified, and other processors can load this cache line into cache.
- Invalid: Cache line contains no meaningful data.
According to our CPU cache structure diagram, assuming all CPUs share the same bus, the following messages are sent on the bus:
- Read: This event contains the physical address of the cache line to be read.
- Read Response: Contains data requested by the previous read event. Data can come from memory or other caches. For example, if requested data is in modified state in another cache, the cache line data must be read from that cache as Read Response.
- Invalidate: This event contains the physical address of the cache line to be expired. Other caches must remove this cache line and respond with Invalidate Acknowledge message.
- Invalidate Acknowledge: After receiving Invalidate message and removing the corresponding cache line, respond with Invalidate Acknowledge message.
- Read Invalidate: Combination of Read and Invalidate messages, containing the physical address of the cache line to be read. Both reads this cache line requiring Read Response, and sends to other caches to remove this cache line and respond with Invalidate Acknowledge.
- Writeback: This message contains the memory address and data to be updated. This message also allows cache lines in modified state to be evicted to make room for other data.
Relationship between cache line state transitions and events:
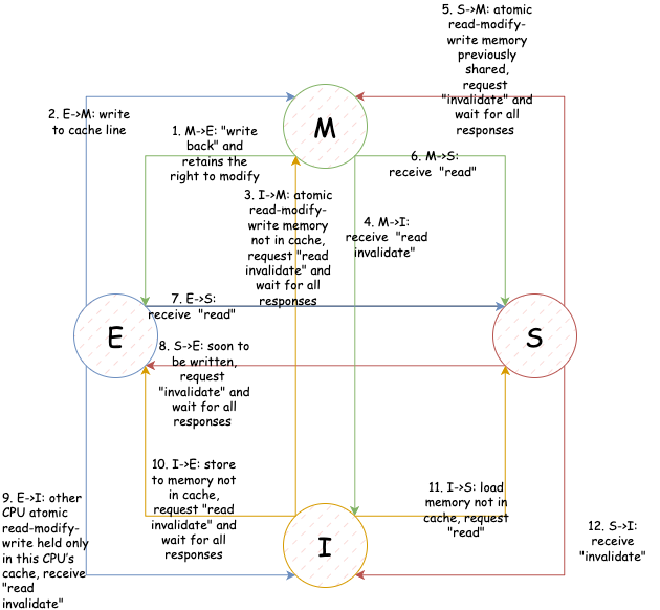
This diagram is just listed here. We won’t go into detail because MESI is a very streamlined protocol, and there are many additional problems MESI cannot solve in actual implementation. If we explained in detail, readers would get confused thinking about how this protocol should work in extreme cases, but MESI actually cannot solve these. In actual implementation, CPU consistency protocols are much more complex than MESI, but are generally based on MESI extensions.
Here’s a simple MESI example:
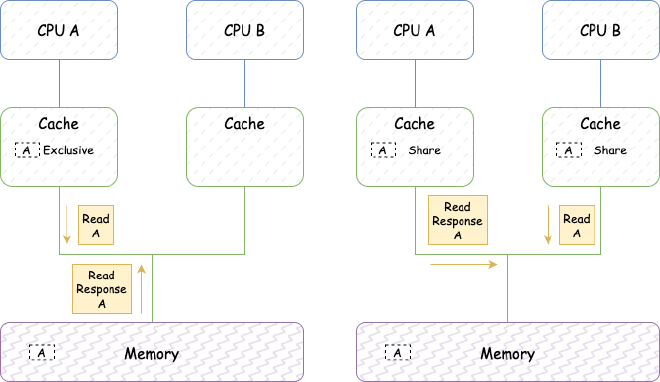
CPU A sends Read to read data from address a, receives Read Response, stores data in its cache and sets the corresponding cache line to Exclusive
CPU B sends Read to read data from address a. CPU A detects address conflict, CPU A responds with Read Response returning cache line data containing address a. After that, data at address a is loaded into both A and B caches in Shared state.
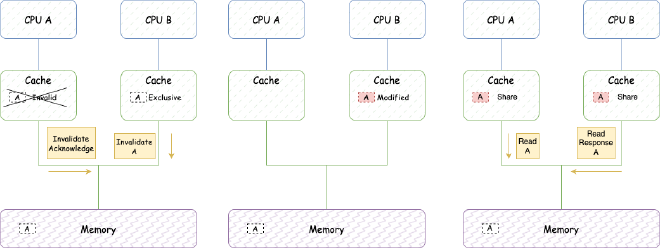
CPU B is about to write to a, sends Invalidate, waits for CPU A’s Invalidate Acknowledge response, then changes state to Exclusive. CPU A receives Invalidate, sets the cache line containing a to Invalid state.
CPU B modifies data and stores it in the cache line containing address a, setting cache line state to modified.
Now CPU A needs data a again, sends Read to read data from address a. CPU B detects address conflict, CPU B responds with Read Response returning cache line data containing address a. After that, data at address a is loaded into both A and B caches in Shared state.
We can see that in MESI protocol, sending Invalidate messages requires the current CPU to wait for Invalidate Acknowledge from other CPUs, i.e., there’s CPU Stall here. To avoid this Stall, Store Buffer was introduced.
5.2.3. Simplified CPU Model - Avoiding Stall from Waiting for Invalidate Response - Store Buffer#
To avoid this Stall, a Store Buffer is added between CPU and CPU cache, as shown below:
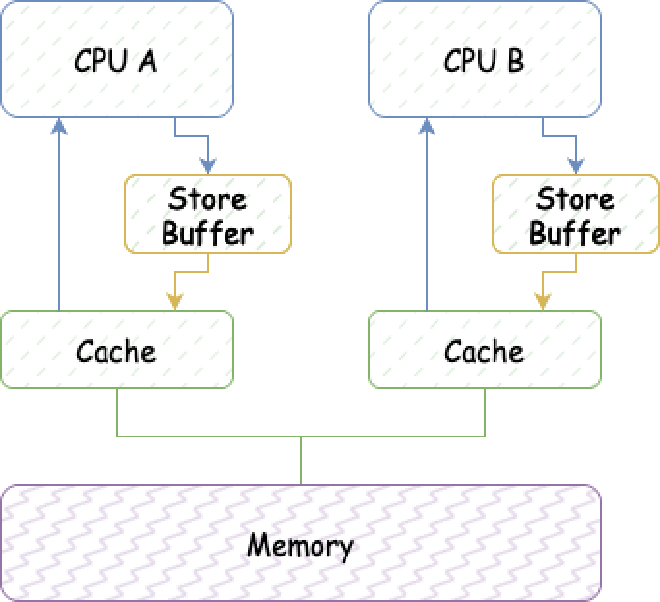
With Store Buffer, when the CPU sends Invalidate messages, it doesn’t need to wait for Invalidate Acknowledge responses. It directly puts modified data into Store Buffer. When all Invalidate Acknowledge responses are received, data is moved from Store Buffer to the corresponding cache line in CPU cache. But adding Store Buffer brings new problems:
Assume two variables a and b that won’t be in the same cache line, both initially 0. Variable a is now in CPU A’s cache line, b is now in CPU B’s cache line.
Assume CPU B executes the following code:
a = 1;
b = a + 1;
assert(b == 2)
We certainly expect b to equal 2 in the end. But will it really be as we wish? Let’s look at this detailed execution sequence:
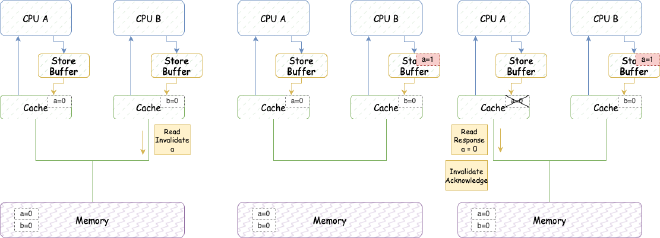
- CPU B executes a = 1:
(1) Since CPU B’s cache doesn’t have a and needs to modify it, it issues Read Invalidate message (because it needs to read the entire cache line containing a before updating, so it sends Read Invalidate, not just Invalidate).
(2) CPU B puts a’s modification (a=1) into Storage Buffer.
(3) CPU A receives Read Invalidate message, marks the cache line containing a as Invalid and removes it from cache, responds with Read Response (a=0) and Invalidate Acknowledge.
- CPU B executes b = a + 1:
(1) CPU B receives Read Response from CPU A, where a is still 0.
(2) CPU B stores the result of a + 1 (0+1=1) in the cache containing b.
- CPU B executes assert(b == 2) and fails.
The error is mainly because we didn’t consider reading the latest value from store buffer when loading to cache. So we can add a step to read the latest value from store buffer when loading to cache. This way, we can ensure that b ends up being 2 in the result we saw above:
5.2.4. Simplified CPU Model - Avoiding Out-of-Order Execution from Store Buffer - Memory Barriers#
Let’s look at another example: assume two variables a and b that won’t be in the same cache line, both initially 0. Assume CPU A (cache line contains b, this cache line state is Exclusive) executes:
void foo(void)
{
a = 1;
b = 1;
}
Assume CPU B executes:
void bar(void)
{
while (b == 0) continue;
assert(a == 1);
}
If everything executes in program order as expected, we expect CPU B’s execution of assert(a == 1) to succeed. But let’s look at this execution flow:
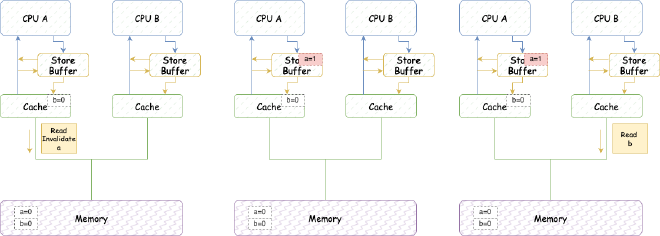
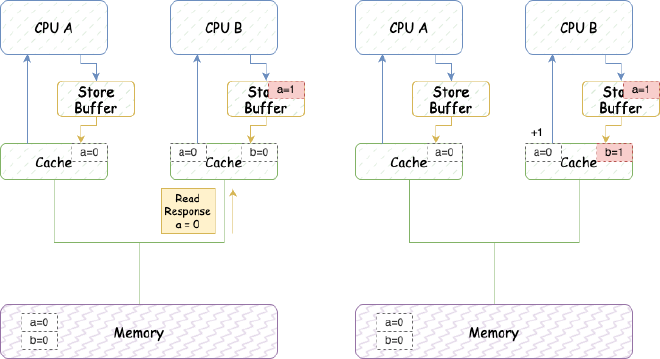
- CPU A executes a = 1:
(1) CPU A’s cache doesn’t have a and needs to modify it, so it issues Read Invalidate message.
(2) CPU A puts a’s modification (a=1) into Storage Buffer.
- CPU B executes while (b == 0) continue:
(1) CPU B’s cache doesn’t have b, issues Read message.
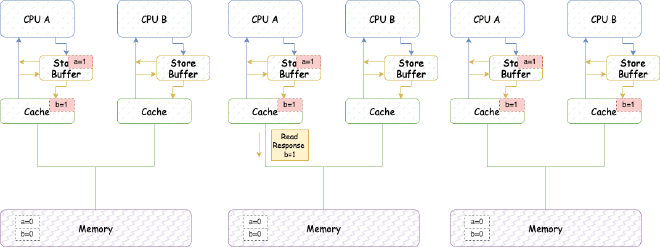
- CPU A executes b = 1:
(1) CPU A’s cache line has b and state is Exclusive, directly updates cache line.
(2) Then, CPU A receives Read message from CPU B about b.
(3) CPU A responds with cached b = 1, sends Read Response message, and changes cache line state to Shared.
(4) CPU B receives Read Response message, puts b into cache.
(5) CPU B can exit the loop because CPU B sees b is now 1.
- CPU B executes assert(a == 1), but since a’s change hasn’t been updated yet, it fails.
For such reordering, CPUs generally cannot automatically control it, but usually provide memory barrier instructions to tell the CPU to prevent reordering, for example:
void foo(void)
{
a = 1;
smp_mb();
b = 1;
}
smp_mb() will make the CPU flush Store Buffer contents into cache. After adding this memory barrier instruction, the execution flow becomes:
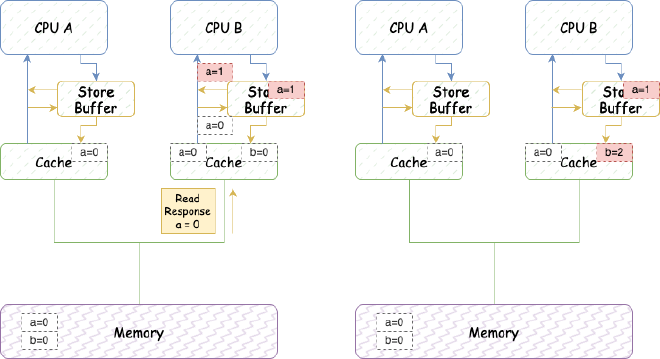
- CPU A executes a = 1:
(1) CPU A’s cache doesn’t have a and needs to modify it, so it issues Read Invalidate message.
(2) CPU A puts a’s modification (a=1) into Storage Buffer.
- CPU B executes while (b == 0) continue:
(1) CPU B’s cache doesn’t have b, issues Read message.
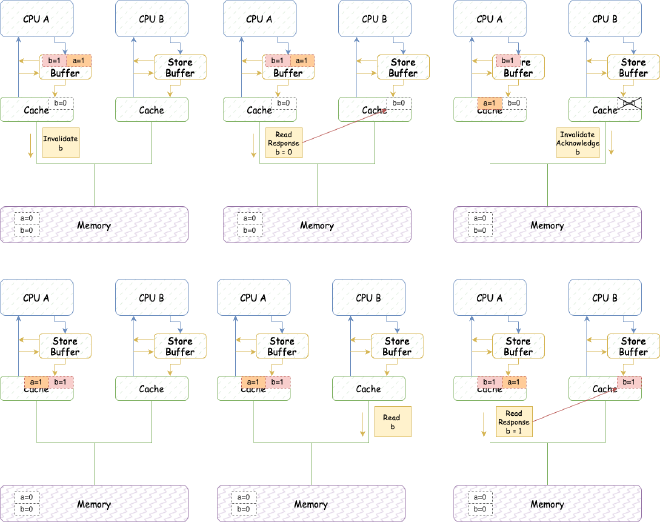
- CPU A executes smp_mb():
(1) CPU A marks all entries in current Store Buffer (currently only a, so mark a).
- CPU A executes b = 1:
(1) CPU A’s cache line has b and state is Exclusive, but since Store Buffer has marked entry a, it doesn’t directly update cache line but puts it into Store Buffer (unlike a, without marking). Issues Invalidate message.
(2) Then, CPU A receives Read message from CPU B about b.
(3) CPU A responds with cached b = 0, sends Read Response message, and changes cache line state to Shared.
(4) CPU B receives Read Response message, puts b into cache.
(5) CPU B continues looping because CPU B sees b is still 0.
(6) CPU A receives responses related to previous “Read Invalidate” for a, flushes marked entry a from Store Buffer into cache, this cache line state becomes modified.
(7) CPU B receives Invalidate message for b from CPU A, invalidates b’s cache line, replies Invalidate Acknowledge.
(8) CPU A receives Invalidate Acknowledge, flushes b from Store Buffer into cache.
(9) Since CPU B continuously reads b but b is no longer in cache, it sends Read message.
(10) CPU A receives Read message from CPU B, sets b’s cache line state to shared, returns Read Response with cached b = 1.
(11) CPU B receives Read Response, learns b = 1, puts it into cache line with shared state.
CPU B learns b = 1, exits while (b == 0) continue loop.
CPU B executes assert(a == 1) (this is simpler, so no diagram): (1) CPU B’s cache doesn’t have a, issues Read message. (2) CPU A reads a = 1 from cache, responds Read Response. (3) CPU B executes assert(a == 1) successfully.
Store Buffer is generally quite small. If Store Buffer becomes full, Stall problems will still occur. We want Store Buffer to flush into CPU cache quickly, which happens after receiving corresponding Invalidate Acknowledge. However, other CPUs might be busy and can’t quickly respond to received Invalidate messages with Invalidate Acknowledge, potentially causing Store Buffer to fill up and cause CPU Stall. So, each CPU’s Invalidate queue can be introduced to buffer Invalidate messages to be processed.
5.2.5. Simplified CPU Model - Decoupling CPU Invalidate and Store Buffer - Invalidate Queues#
After adding Invalidate Queues, the CPU structure is as follows:

With Invalidate Queue, the CPU can put Invalidate into this queue and immediately flush corresponding data from Store Buffer into CPU cache. Also, before a CPU wants to actively send Invalidate messages for a cache line, it must check if there are Invalidate messages for the same cache line in its own Invalidate Queue. If there are, it must wait to process corresponding messages in its own Invalidate Queue first.
Similarly, Invalidate Queue also brings out-of-order execution.
5.2.6. Simplified CPU Model - Further Reordering from Invalidate Queues - Memory Barriers Needed#
Assume two variables a and b that won’t be in the same cache line, both initially 0. Assume CPU A (cache line contains a(shared), b(Exclusive)) executes:
void foo(void)
{
a = 1;
smp_mb();
b = 1;
}
CPU B (cache line contains a(shared)) executes:
void bar(void)
{
while (b == 0) continue;
assert(a == 1);
}
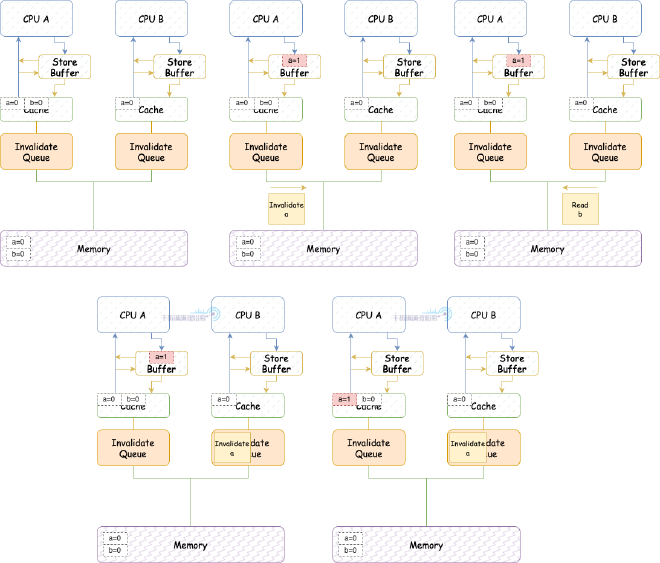
- CPU A executes a = 1:
(1) CPU A’s cache has a (shared), CPU A puts a’s modification (a=1) into Store Buffer, sends Invalidate message.
- CPU B executes while (b == 0) continue:
(1) CPU B’s cache doesn’t have b, issues Read message.
(2) CPU B receives Invalidate message from CPU A, puts it into Invalidate Queue and immediately returns.
(3) CPU A receives Invalidate message response, flushes cache line from Store Buffer into CPU cache.
- CPU A executes smp_mb():
(1) Since CPU A has already flushed cache line from Store Buffer into CPU cache, this passes directly.
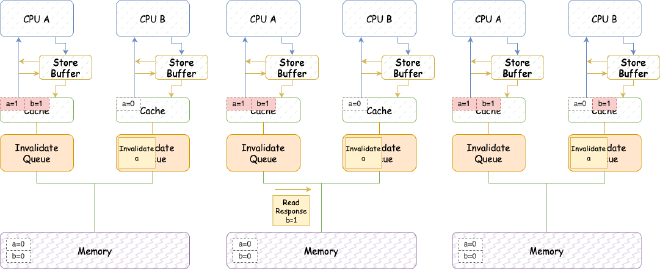
- CPU A executes b = 1:
(1) Since CPU A contains b’s cache line (Exclusive), it directly updates the cache line.
(2) CPU A receives Read message sent earlier by CPU B, updates b’s cache line state to Shared, then sends Read Response containing b’s latest value.
(3) CPU B receives Read Response, b’s value is 1.
- CPU B exits loop, starts executing assert(a == 1):
(1) Since Invalidate message about a is still in Invalidate queue unprocessed, CPU B still sees a = 0, assert fails.
So, for this reordering, we also add memory barriers in CPU B’s executed code. Here memory barriers not only wait for CPU to flush all Store Buffer, but also wait for CPU’s Invalidate Queue to be completely processed. Adding memory barriers, CPU B executes:
void bar(void)
{
while (b == 0) continue;
smp_mb();
assert(a == 1);
}
This way, in step 5 above, CPU B exits loop and needs to wait for Invalidate queue to be completely processed before executing assert(a == 1): (1) Process Invalidate message, set b to Invalid. (2) Continue code, execute assert(a == 1). Since b doesn’t exist in cache now, need to send Read message, this way can see b’s latest value 1, assert succeeds.
5.2.7. Simplified CPU Model - Finer-Grained Memory Barriers#
We mentioned earlier that in our CPU model, smp_mb() memory barrier instruction does two things: wait for CPU to flush all Store Buffer, wait for CPU’s Invalidate Queue to be completely processed. However, for memory barriers in code executed by CPU A and CPU B here, these two operations don’t always need to exist simultaneously:
void foo(void)
{
a = 1;
smp_mb();//Only needs to wait for CPU to flush all Store Buffer
b = 1;
}
void bar(void)
{
while (b == 0) continue;
smp_mb();//Only needs to wait for CPU's Invalidate Queue to be completely processed
assert(a == 1);
}
So, CPUs generally also abstract finer-grained memory barrier instructions. We call the instruction that waits for CPU to flush all Store Buffer a write memory barrier (Write Memory Barrier), and the instruction that waits for CPU’s Invalidate Queue to be completely processed a read memory barrier (Read Memory Barrier).
5.2.8. Simplified CPU Model - Summary#
Through a simple CPU architecture, we’ve progressively explained some simplified CPU structures and why memory barriers are needed. This can be summarized in the following simple thought process flowchart:
- Direct CPU memory access is too slow each time, keeping CPU in Stall waiting. To reduce CPU Stall, CPU cache was added.
- CPU cache brought cache inconsistency between multiple CPUs, so MESI simple CPU cache coherence protocol coordinates cache consistency between different CPUs.
- Optimizing some mechanisms in MESI protocol to further reduce CPU Stall:
- By putting updates into Store Buffer, updates don’t need CPU Stall waiting for Invalidate Response from Invalidate messages.
- Store Buffer brought instruction (code) reordering, requiring memory barrier instructions to force current CPU Stall waiting to flush all Store Buffer contents. This memory barrier instruction is generally called write barrier.
- To speed up Store Buffer flushing into cache, Invalidate Queue was added, but this brought further reordering requiring read barriers.
5.3. CPU Instruction Reordering#
CPU instruction execution can also be reordered. We’ll only mention one common type - instruction parallelization.
5.3.1. Increasing CPU Execution Efficiency - CPU Pipeline Mode#
Modern CPUs execute instructions in pipeline mode. Since CPUs have different internal components, we can divide executing one instruction into different stages involving different components. This pseudo-decoupling allows each component to execute independently without waiting for one instruction to complete before processing the next.
Generally divided into these stages: Instruction Fetch (IF), Instruction Decode (ID), Execute (EXE), Memory (MEM), Write-Back (WB)

5.3.2. Further Reducing CPU Stall - CPU Out-of-Order Execution Pipeline#
Since instruction data readiness is also uncertain, consider this example:
b = a + 1;
c = 1;
If data a isn’t ready and hasn’t been loaded into registers, we don’t need to Stall waiting for a to load - we can execute c = 1 first. Thus, we can extract parallelizable instructions from programs and schedule them for simultaneous execution. CPU out-of-order execution pipeline is based on this approach:
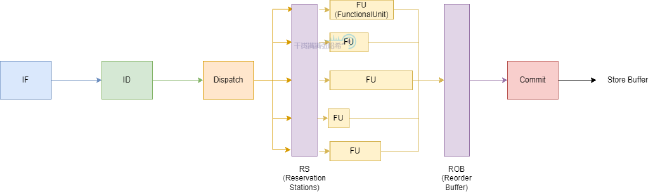
As shown, CPU execution stages are divided into:
- Instructions Fetch: Batch fetch instructions, analyze loops, dependencies, branch prediction, etc.
- Instruction Decode: Instruction decoding, similar to previous pipeline mode
- Reservation stations: Instructions needing operand input enter Functional Unit (FU) if input is ready; if not ready, monitor Bypass network for data readiness signals to Reservation stations to let instructions enter FU processing.
- Functional Unit: Process instructions
- Reorder Buffer: Saves instructions in original program order. Instructions are added to one end of the list after being dispatched and removed from the other end when execution completes. This way, instructions complete in their dispatch order.
This structural design ensures Store Buffer write order matches original instruction order. However, data loading and computation execute in parallel. We already know from our simplified CPU architecture that multi-CPU cache MESI, Store Buffer, and Invalidate Queue prevent reading latest values. The parallel loading and processing here exacerbates this.
Moreover, this structural design can only detect mutual dependencies between instructions in the same thread, ensuring correct execution order for such interdependent instructions. But instruction dependencies between multi-threaded programs cannot be sensed by CPU batch instruction fetching and branch prediction. So reordering still occurs. This reordering can also be avoided through the memory barriers mentioned earlier.
5.4. Actual CPUs#
Actual CPUs are diverse, with different CPU structural designs and different CPU cache coherence protocols, resulting in different types of reordering. Looking at each individually would be too complex. So, people use a standard to abstractly describe different CPU reordering phenomena (i.e., whether first operation M and second operation N will reorder - very similar to Doug Lea’s JMM description, as Java Memory Model also references this design). Reference this table:
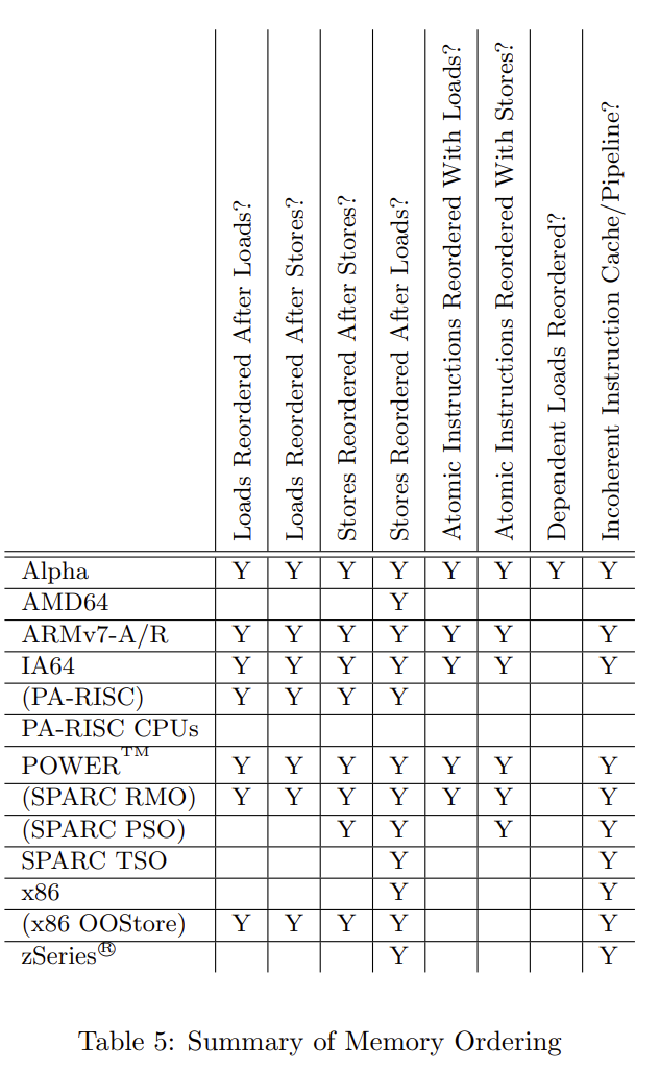
Let’s explain each column:
- Loads Reordered After Loads: First operation is read, second is also read, whether they reorder.
- Loads Reordered After Stores: First operation is read, second is write, whether they reorder.
- Stores Reordered After Stores: First operation is write, second is also write, whether they reorder.
- Stores Reordered After Loads: First operation is write, second is read, whether they reorder.
- Atomic Instructions Reordered With Loads: Whether atomic operations (group operations happening simultaneously, like instructions modifying two words at once) and reads reorder with each other.
- Atomic Instructions Reordered With Stores: Whether atomic operations and writes reorder with each other.
- Dependent Loads Reordered: Whether reads depending on another read’s result will reorder.
- Incoherent Instruction Cache/Pipeline: Whether instruction out-of-order execution occurs.
For example, the commonly used x86 architecture on our PCs only has Stores Reordered After Loads and Incoherent Instruction Cache/Pipeline. This is why among the LoadLoad, LoadStore, StoreLoad, StoreStore four Java memory barriers mentioned later, only StoreLoad needs implementation on x86 environments.
5.5. Compiler Reordering#
Besides CPU reordering, there’s also compiler optimization reordering at the software level. Compiler optimization approaches are actually somewhat similar to CPU instruction pipeline optimization mentioned above. Compilers also analyze your code and optimize mutually independent statements. For mutually independent statements, they can be freely reordered. But similarly, compilers can only consider and analyze from single-threaded perspective, not knowing your program’s dependencies and connections in multi-threaded environments.
Here’s another simple example: assuming no CPU reordering environment, with two variables x = 0, y = 0, thread 1 executes:
x = 1;
y = 1;
Thread 2 executes:
while(y == 1);
assert(x == 1);
Thread 2 might fail assert because compilers might reorder x = 1 and y = 1.
Compiler reordering can be avoided by adding compiler barrier statements for different operating systems. For example, thread 1 executes:
x = 1;
compiler_barrier();
y = 1;
This prevents reordering between x = 1 and y = 1.
Also, in actual use, memory barriers generally refer to hardware memory barriers implemented through hardware CPU instructions. Such hardware memory barriers generally also implicitly include compiler barriers. Compiler barriers are generally called software memory barriers, only controlling compiler software-level barriers. For example, volatile in C++ is different from Java’s volatile - C++’s volatile only prohibits compiler reordering (has compiler barriers) but cannot avoid CPU reordering.
Above, we’ve basically clarified reordering sources and memory barrier functions. Next, we’ll enter the main topic and begin our Java 9+ Memory Model journey. Before that, let’s mention one more important point: why it’s best not to write your own code to verify JMM conclusions, but use professional frameworks for testing.
6. Why It’s Best Not to Write Your Own Code to Verify JMM Conclusions#
Through previous analysis, we know program reordering problems are complex. Suppose some code has no restrictions - all possible output results form a universal set. Under Java Memory Model restrictions, possible results are limited to a subset of all reordering results:
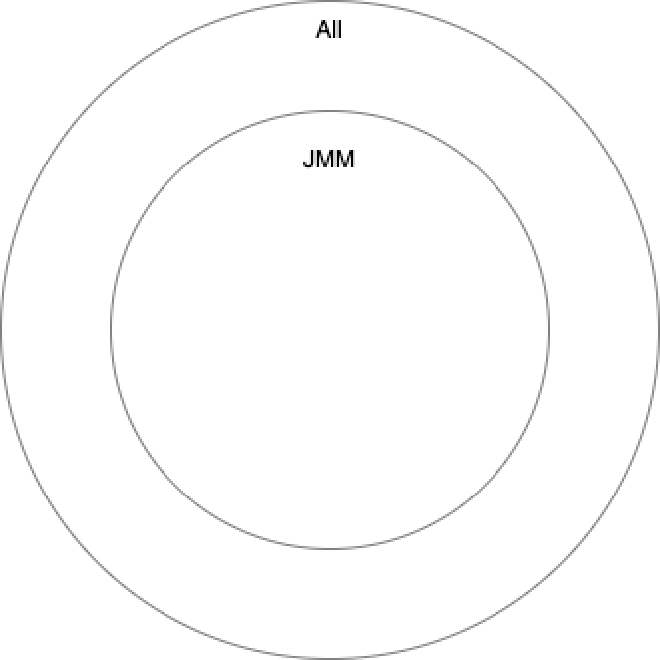
Under Java Memory Model restrictions, on different CPU architectures with different CPU reordering situations, some scenarios cause reordering on some CPUs but not others, yet all are within JMM scope so are reasonable. This further limits possible result sets to different subsets of JMM:
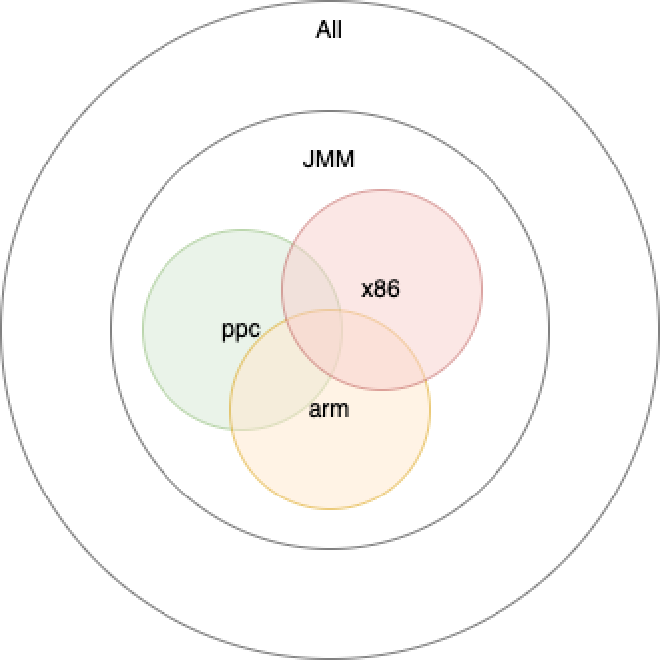
Under Java Memory Model restrictions, different operating system compilers compile different JVM code execution orders, different underlying system call definitions. Java code execution on different operating systems might have slight differences, but since all are within JMM restriction scope, they’re also reasonable:
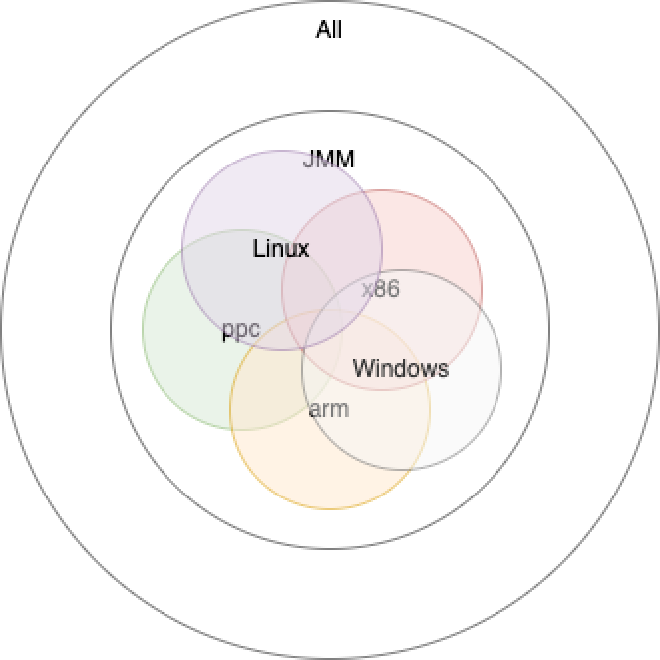
Finally, under different execution methods and JIT compilation, underlying executed code still differs, further causing result set differentiation:
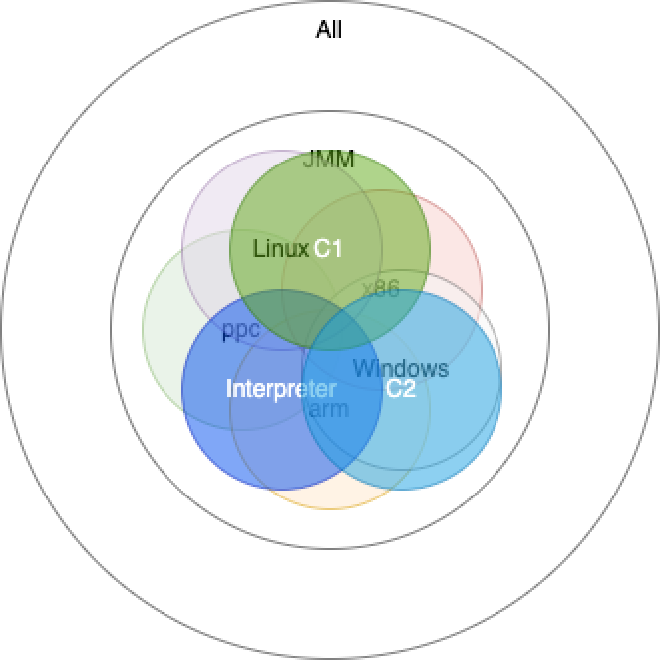
So, if you write code to test on your single computer with single operating system, the result set you can test is only a subset of JMM. You likely won’t see some reordering results. Moreover, some reordering won’t be visible with few executions or without JIT optimization, so writing your own test code really isn’t recommended.
What should you do? Use the relatively official framework for testing concurrency visibility - jcstress. While this framework can’t simulate different CPU architectures and operating systems, it can help you exclude different execution reasons (interpretation execution, C1 execution, C2 execution) and insufficient test pressure. All following explanations will include corresponding jcstress code examples for everyone to use.
7. Progressive Visibility and Java 9+ Memory Model Corresponding APIs#
This mainly references Aleksey’s approach to summarize different levels of progressively increasing Java memory visibility restriction properties and corresponding APIs. In Java 9+, ordinary variable access (non-volatile, final variables) is defined as Plain. Ordinary access has no barriers for the accessed address (not GC barriers like generational GC pointer barriers - those are only GC-level and don’t affect visibility here), experiencing all reorderings mentioned earlier. So what restrictions does Java 9+ Memory Model propose and what are the corresponding APIs? Let’s explain progressively.
7.1. Coherence and Opaque#
| Java 9+ VarHandle API | Compiler Barrier | Memory Barrier | Coherence | Causality | Consensus |
|---|---|---|---|---|---|
| Plain (ordinary field access) | None | None | Not guaranteed | Not guaranteed | Not guaranteed |
| Opaque (similar to C++ volatile) | Yes | None | Guaranteed | Not guaranteed | Not guaranteed |
I’m not sure how to translate the title because many places online translate CPU Cache Coherence Protocol as CPU cache consistency protocol, meaning Coherence represents consistency in that context. But translating Coherence as consistency here wouldn’t be appropriate. So I’ll directly use Doug Lea’s and Aleksey’s definitions for subsequent terms.
What is coherence here? Here’s a simple example: suppose object field int x initially 0, one thread executes:
x = 1;
Another thread executes (r1, r2 are local variables):
int r1 = x;
int r2 = x;
Under Java Memory Model, possible results include:
r1 = 1, r2 = 1r1 = 0, r2 = 1r1 = 1, r2 = 0r1 = 0, r2 = 0
The third result is interesting - from program understanding, we first saw x = 1, then saw x become 0. Of course, through previous analysis, we know this is actually due to compiler reordering. If we don’t want to see this third result, the property we need is coherence.
Coherence definition, quoting the original:
The writes to the single memory location appear to be in a total order consistent with program order.
This means writes to single memory locations appear to be in total order consistent with program order. This seems hard to understand. Combined with the above example, it can be understood as: globally, x changed from 0 to 1, so each thread should only see x change from 0 to 1, not possibly see it change from 1 to 0.
As mentioned earlier, Plain reads and writes in Java Memory Model definition cannot guarantee coherence. But if you run test code for the above, you won’t get the third result. This is because semantic analysis in HotSpot virtual machine considers these two reads (loads) of x as mutually dependent, thus limiting this reordering:
@JCStressTest
@State
@Outcome(id = "1, 1", expect = ACCEPTABLE, desc = "ordered")
@Outcome(id = "0, 1", expect = ACCEPTABLE, desc = "ordered")
@Outcome(id = "1, 0", expect = ACCEPTABLE_INTERESTING, desc = "reordered")
@Outcome(id = "0, 0", expect = ACCEPTABLE, desc = "ordered")
public class TestCoherence {
int x;
@Actor
public void actor1(){
x = 1;
}
@Actor
public void actor2(II_Result result){
result.r1 = x;
result.r2 = x;
}
}
This is why I mentioned earlier why it’s best not to write your own code to verify JMM conclusions. Although Java Memory Model restrictions allow the third result 1, 0, you can’t test it with this example.
We’ll use an awkward example to trick the Java compiler into causing this reordering:
@JCStressTest
@State
@Outcome(id = "1, 1", expect = ACCEPTABLE, desc = "ordered")
@Outcome(id = "0, 1", expect = ACCEPTABLE, desc = "ordered")
@Outcome(id = "1, 0", expect = ACCEPTABLE_INTERESTING, desc = "reordered")
@Outcome(id = "0, 0", expect = ACCEPTABLE, desc = "ordered")
public class TestCoherence {
//h1,h2 are actually the same object
private final Holder h1 = new Holder();
private final Holder h2 = h1;
private static class Holder {
//This is the field we want to access
int a;
//This field is mainly added to trick the compiler
int trap;
}
@Actor
public void actor1(){
//One thread updates the field
h1.a = 1;
}
@Actor
public void actor2(II_Result result){
//Another thread reads
final Holder h1 = this.h1;
final Holder h2 = this.h2;
//Initialize, so subsequent loads of h1,h2 will be non-mutually dependent loads
h1.trap = 1;
h2.trap = 1;
result.r1 = h1.a;
result.r2 = h2.a;
}
}
We don’t need to delve into the principle, just look at the result:
Scheduling class:
actor1: package group free, core group free
actor2: package group free, core group free
CPU allocation: unspecified
Compilation: split
actor1: C2
actor2: C2
JVM args: [-Dfile.encoding=GBK]
Fork: #1
RESULT SAMPLES FREQ EXPECT DESCRIPTION
0, 0 12,077,605 19.67% Acceptable ordered
0, 1 54 <0.01% Acceptable ordered
1, 0 50,481 0.08% Interesting reordered
1, 1 49,262,708 80.24% Acceptable ordered
We found reordering occurred, and if you run this example yourself, you’ll find this reordering only appears when actor2 method executes after JIT C2 compilation.
How to avoid this reordering? Using volatile would certainly work, but we don’t need such heavy operations. Just use Opaque access. Opaque actually just prohibits Java compiler optimization but doesn’t involve any memory barriers, very similar to C++’s volatile. Let’s test:
@JCStressTest
@State
@Outcome(id = "1, 1", expect = ACCEPTABLE, desc = "ordered")
@Outcome(id = "0, 1", expect = ACCEPTABLE, desc = "ordered")
@Outcome(id = "1, 0", expect = ACCEPTABLE_INTERESTING, desc = "reordered")
@Outcome(id = "0, 0", expect = ACCEPTABLE, desc = "ordered")
public class TestCoherence {
static final VarHandle VH;
static {
try {
VH = MethodHandles.lookup().findVarHandle(Holder.class, "a", int.class);
} catch (NoSuchFieldException | IllegalAccessException e) {
throw new IllegalStateException(e);
}
}
private final Holder h1 = new Holder();
private final Holder h2 = h1;
private static class Holder {
int a;
int trap;
}
@Actor
public void actor1(){
h1.a = 1;
}
@Actor
public void actor2(II_Result result){
final Holder h1 = this.h1;
final Holder h2 = this.h2;
h1.trap = 1;
h2.trap = 1;
//This way, there won't be reordering
result.r1 = (int) VH.getOpaque(h1);
result.r2 = (int) VH.getOpaque(h2);
}
}
Running this, we can see there’s no reordering (if command line has no ACCEPTABLE_INTERESTING, FORBIDDEN, UNKNOWN results, they won’t be output - only visible in final HTML output):
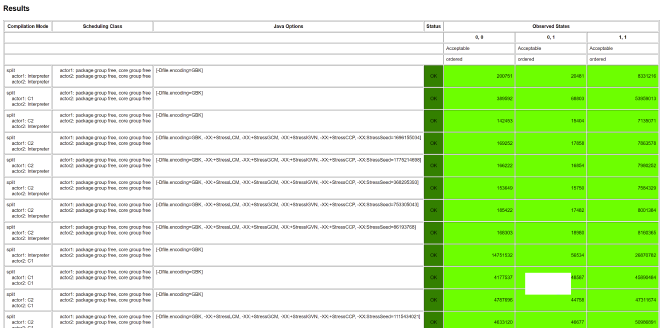
7.2. Causality and Acquire/Release#
| Java 9+ VarHandle API | Compiler Barrier | Memory Barrier | Coherence | Causality | Consensus |
|---|---|---|---|---|---|
| Plain (ordinary field access) | None | None | Not guaranteed | Not guaranteed | Not guaranteed |
| Opaque (similar to C++ volatile) | Yes | None | Guaranteed | Not guaranteed | Not guaranteed |
| Release/Acquire | Yes | Release: LoadStore + StoreStore before; Acquire: LoadLoad + LoadStore after | Guaranteed | Guaranteed | Not guaranteed |
Based on Coherence, we generally also need Causality in certain scenarios
Generally here, people encounter two common terms: happens-before and synchronized-with order. We won’t start with these somewhat obscure concepts (specific concept explanations won’t be in this chapter), but through an example: suppose object field int x initially 0, int y also initially 0, these two fields are not in the same cache line (jcstress framework will automatically handle cache line padding for us), one thread executes:
x = 1;
y = 1;
Another thread executes (r1, r2 are local variables):
int r1 = y;
int r2 = x;
This example is very similar to the reordering analysis example in our CPU cache section. Under Java Memory Model, possible results are:
r1 = 1, r2 = 1r1 = 0, r2 = 1r1 = 1, r2 = 0r1 = 0, r2 = 0
Similarly, the third result is interesting - the second thread first saw y update but didn’t see x update. We analyzed this in detail in the CPU cache reordering section. In that analysis, we needed to add memory barriers like this to avoid the third situation:
x = 1;
write_barrier();
y = 1;
and
int r1 = y;
read_barrier();
int r2 = x;
Briefly reviewing: thread 1 executes write barrier after x = 1 and before y = 1, ensuring all Store Buffer updates are updated to cache, guaranteeing updates before y = 1 won’t be invisible due to being in Store Buffer. Thread 2 executes read barrier after int r1 = y, ensuring all data in invalidate queue that needs invalidation is invalidated, ensuring current cache has no dirty data. This way, if thread 2 sees y’s update, it will definitely see x’s update.
Let’s describe this more vividly: we understand write barrier and subsequent Store (i.e., y = 1) as packaging previous updates and launching this package at this point. Read barrier and previous Load (i.e., int r1 = y) are understood as a receiving point - if the launched package is received, the package is opened and read here. So, as shown below:
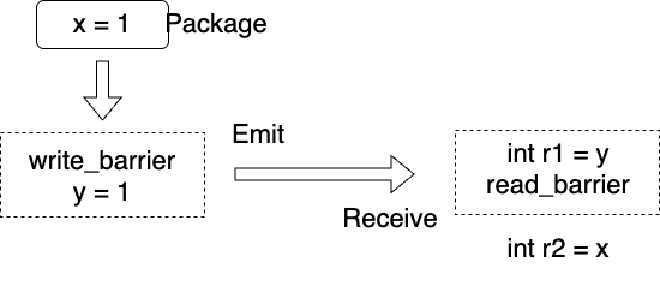
At the launch point, all results before (including the launch point itself) are packaged. If the package is received when executing receiving point code, then all instructions after this receiving point can see all contents in the package, i.e., contents before and at the launch point. Causality (sometimes called Causal Consistency in different contexts) specifically refers to: a series of write operations can be defined such that if a read sees the last write, then all read operations after this read can see this write and all previous writes. This is Partial Order, not Total Order - this definition will be detailed in later chapters.
In Java, neither Plain access nor Opaque access can guarantee Causality, because Plain has no memory barriers and Opaque only has compiler barriers. We can test this with the following code:
First Plain:
@JCStressTest
@State
@Outcome(id = "1, 1", expect = ACCEPTABLE, desc = "ordered")
@Outcome(id = "0, 1", expect = ACCEPTABLE, desc = "ordered")
@Outcome(id = "1, 0", expect = ACCEPTABLE_INTERESTING, desc = "reordered")
@Outcome(id = "0, 0", expect = ACCEPTABLE, desc = "ordered")
public class TestCausality {
int x;
int y;
@Actor
public void actor1() {
x = 1;
y = 1;
}
@Actor
public void actor2(II_Result result) {
result.r1 = y;
result.r2 = x;
}
}
Result:
RESULT SAMPLES FREQ EXPECT DESCRIPTION
0, 0 1,004,331,860 32.89% Acceptable ordered
0, 1 9,094,601 0.30% Acceptable ordered
1, 0 1,713,825 0.06% Interesting reordered
1, 1 2,038,722,626 66.76% Acceptable ordered
Then Opaque:
@JCStressTest
@State
@Outcome(id = "1, 1", expect = ACCEPTABLE, desc = "ordered")
@Outcome(id = "0, 1", expect = ACCEPTABLE, desc = "ordered")
@Outcome(id = "1, 0", expect = ACCEPTABLE_INTERESTING, desc = "reordered")
@Outcome(id = "0, 0", expect = ACCEPTABLE, desc = "ordered")
public class TestCausality {
static final VarHandle VH_X;
static final VarHandle VH_Y;
static {
try {
VH_X = MethodHandles.lookup().findVarHandle(TestCausality.class, "x", int.class);
VH_Y = MethodHandles.lookup().findVarHandle(TestCausality.class, "y", int.class);
} catch (NoSuchFieldException | IllegalAccessException e) {
throw new IllegalStateException(e);
}
}
int x;
int y;
@Actor
public void actor1() {
VH_X.setOpaque(this, 1);
VH_Y.setOpaque(this, 1);
}
@Actor
public void actor2(II_Result result) {
result.r1 = (int) VH_Y.getOpaque(this);
result.r2 = (int) VH_X.getOpaque(this);
}
}
Note: Since we saw earlier that x86 CPUs naturally guarantee some instructions don’t reorder, we’ll soon see which non-reordering guarantees ensure Causality here, so x86 CPUs can’t see reordering, and Opaque access can see causal consistency results, as shown below (AMD64 is an x86 implementation):
But if we switch to other slightly weaker consistency CPUs, we can see Opaque access can’t guarantee causal consistency. Below is my result on aarch64 (an ARM implementation):

Also interesting is that reordering only occurs when executing C2 compilation.
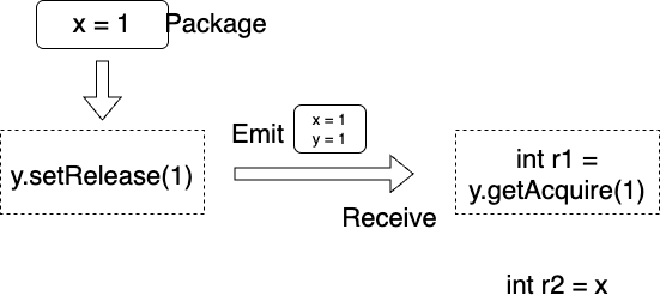
How do we guarantee Causality? Similarly, we don’t need such heavy operations as volatile - using release/acquire mode is sufficient. Release/acquire can guarantee Coherence + Causality. Release/acquire must appear in pairs (one acquire corresponds to one release). We can view release as the launch point mentioned earlier and acquire as the receiving point mentioned earlier, so we can implement code like this:
@JCStressTest
@State
@Outcome(id = "1, 1", expect = ACCEPTABLE, desc = "ordered")
@Outcome(id = "0, 1", expect = ACCEPTABLE, desc = "ordered")
@Outcome(id = "1, 0", expect = ACCEPTABLE_INTERESTING, desc = "reordered")
@Outcome(id = "0, 0", expect = ACCEPTABLE, desc = "ordered")
public class TestCausality {
static final VarHandle VH_X;
static final VarHandle VH_Y;
static {
try {
VH_X = MethodHandles.lookup().findVarHandle(TestCausality.class, "x", int.class);
VH_Y = MethodHandles.lookup().findVarHandle(TestCausality.class, "y", int.class);
} catch (NoSuchFieldException | IllegalAccessException e) {
throw new IllegalStateException(e);
}
}
int x;
int y;
@Actor
public void actor1() {
x = 1;
VH_Y.setRelease(this, 1);
}
@Actor
public void actor2(II_Result result) {
result.r1 = (int) VH_Y.getAcquire(this);
result.r2 = x;
}
}
Then, continuing on the aarch64 machine, the result is:
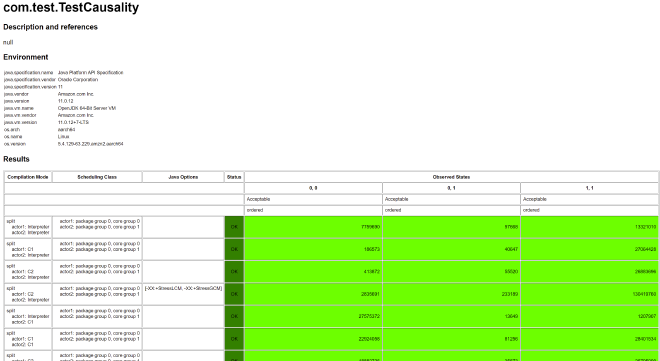
We can see Causality is guaranteed due to using Release/Acquire. Note that launch and receiving point selection must be correct. For example, if we change positions here, it would be wrong:
Example 1: Launch point only packages all previous updates. Since x = 1 update is after the launch point, it’s equivalent to not being packaged, so we’d still see 1,0 result.
@Actor
public void actor1() {
VH_Y.setRelease(this, 1);
x = 1;
}
@Actor
public void actor2(II_Result result) {
result.r1 = (int) VH_Y.getAcquire(this);
result.r2 = x;
}
Example 2: Receiving point unpacks, letting subsequent reads see package contents. Since x reading is before the receiving point, it’s equivalent to not seeing package updates, so we’d still see 1,0 result.
@Actor
public void actor1() {
x = 1;
VH_Y.setRelease(this, 1);
}
@Actor
public void actor2(II_Result result) {
result.r2 = x;
result.r1 = (int) VH_Y.getAcquire(this);
}
By analogy with Doug Lea’s Java memory barrier design, let’s see which Java memory barriers are used here. In Doug Lea’s very early and classic article introducing Java Memory Model and its memory barrier design, he proposed four barriers:
1. LoadLoad
If there are two completely unrelated, independent (i.e., can be reordered) reads (Load), LoadLoad barrier can prevent their reordering (i.e., Load(y) won’t execute before Load(x)):
Load(x);
LoadLoad
Load(y);
2. LoadStore
If there’s a read (Load) and a completely unrelated (i.e., can be reordered) write (Store), LoadStore barrier can prevent their reordering (i.e., Store(y) won’t execute before Load(x)):
Load(x);
LoadStore
Store(y);
3. StoreStore
If there are two completely unrelated, independent (i.e., can be reordered) writes (Store), StoreStore barrier can prevent their reordering (i.e., Store(y) won’t execute before Store(x)):
Store(x);
StoreStore
Store(y);
4. StoreLoad
If there’s a write (Store) and a completely unrelated (i.e., can be reordered) read (Load), StoreLoad barrier can prevent their reordering (i.e., Load(y) won’t execute before Store(x)):
Store(x);
StoreLoad
Load(y);
How are Release/Acquire implemented through these memory barriers? We can deduce from our previous abstraction. First is the launch point. The launch point is first a Store and guarantees packaging everything before, so whether Load or Store, everything must be packaged and can’t run after, so LoadStore and StoreStore memory barriers need to be added before Release. Similarly, the receiving point is a Load and guarantees everything after can see package values, so whether Load or Store can’t run before, so LoadLoad and LoadStore memory barriers need to be added after Acquire.
However, as we’ll see in the next chapter, these four memory barrier designs are somewhat outdated (due to CPU development and C++ language development). JVM internally uses acquire, release, and fence more. The acquire and release here are actually what we mentioned as Release/Acquire. The relationship between these three and traditional four-barrier design is:
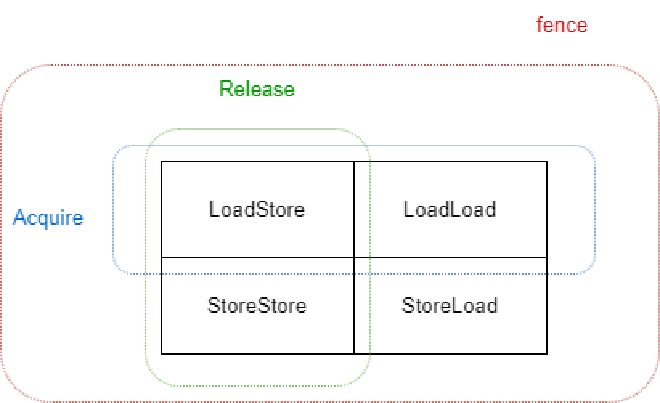
We know Release/Acquire memory barriers. Why doesn’t x86 have this reordering without setting these memory barriers? Reference the previous CPU reordering diagram:
We know x86 doesn’t reorder Store with Store, Load with Load, Load with Store, so it naturally guarantees Causality.
7.3. Consensus and Volatile#
| Java 9+ VarHandle API | Compiler Barrier | Memory Barrier | Coherence | Causality | Consensus |
|---|---|---|---|---|---|
| Plain (ordinary field access) | None | None | Not guaranteed | Not guaranteed | Not guaranteed |
| Opaque (similar to C++ volatile) | Yes | None | Guaranteed | Not guaranteed | Not guaranteed |
| Release/Acquire | Yes | Release: LoadStore + StoreStore before; Acquire: LoadLoad + LoadStore after | Guaranteed | Guaranteed | Not guaranteed |
| Volatile | Yes | Volatile write: LoadStore + StoreStore before; StoreLoad after; Volatile read: LoadLoad + LoadStore after | Guaranteed | Guaranteed | Guaranteed |
Finally we reach familiar Volatile. Volatile actually builds on Release/Acquire to further guarantee Consensus. Consensus means all threads see consistent memory update order, i.e., all threads see globally consistent memory order. Here’s an example: suppose object field int x initially 0, int y also initially 0, these two fields are not in the same cache line (jcstress framework will automatically handle cache line padding), one thread executes:
x = 1;
int r1 = y;
Another executes:
y = 1;
int r2 = x;
Under Java Memory Model, there can be 4 possible results:
r1 = 1, r2 = 1r1 = 0, r2 = 1r1 = 1, r2 = 0r1 = 0, r2 = 0
The fourth result is interesting - it doesn’t conform to Consensus because the two threads see different update orders (the first thread seeing 0 means it thinks x’s update happened before y’s update, the second thread seeing 0 means it thinks y’s update happened before x’s update). Without reordering, we definitely wouldn’t see both x and y as 0, because both thread 1 and thread 2 update first then read. But as explained in all previous discussions, various reorderings cause us to see such results. Can Release/Acquire guarantee we won’t see such results? Let’s analyze briefly. If x and y access are both Release/Acquire mode, then thread 1 actually executes:
LoadStore
StoreStore
x = 1;
int r1 = y;
LoadLoad
LoadStore
We can see there’s no memory barrier between x = 1 and int r1 = y, so it might actually execute:
LoadStore
StoreStore
int r1 = y;
x = 1;
LoadLoad
LoadStore
Similarly, thread 2 might execute:
LoadStore
StoreStore
y = 1;
int r2 = x;
LoadLoad
LoadStore
or:
LoadStore
StoreStore
int r2 = x;
y = 1;
LoadLoad
LoadStore
This way, we might see the fourth result. Let’s test with code:
@JCStressTest
@State
@Outcome(id = "0, 0", expect = ACCEPTABLE_INTERESTING, desc = "not consensus")
//Other results are acceptable but not what we care about
@Outcome(expect = ACCEPTABLE, desc = "boring")
public class TestConsensus {
int x;
int y;
private static final VarHandle X;
private static final VarHandle Y;
static {
try {
//Initialize handles
X = MethodHandles.lookup().findVarHandle(TestConsensus.class, "x", int.class);
Y = MethodHandles.lookup().findVarHandle(TestConsensus.class, "y", int.class);
} catch (Exception e) {
throw new Error(e);
}
}
@Actor
public void actor1(II_Result result) {
X.setRelease(this, 1);
result.r1 = (int) Y.getAcquire(this);
}
@Actor
public void actor2(II_Result result) {
Y.setRelease(this, 1);
result.r2 = (int) X.getAcquire(this);
}
}
Test result:
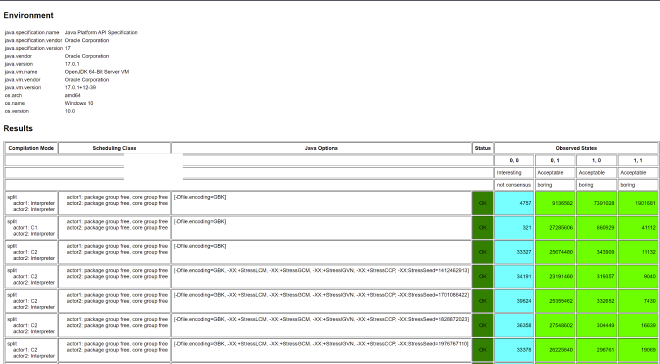
To guarantee Consensus, we just need to ensure thread 1’s code and thread 2’s code don’t reorder, i.e., add StoreLoad memory barrier on top of original memory barriers. Thread 1 executes:
LoadStore
StoreStore
x = 1;
StoreLoad
int r1 = y;
LoadLoad
LoadStore
Thread 2 executes:
LoadStore
StoreStore
y = 1;
StoreLoad
int r2 = x;
LoadLoad
LoadStore
This prevents reordering, which is actually volatile access. Volatile access adds StoreLoad barrier on top of Release/Acquire. Let’s test:
@JCStressTest
@State
@Outcome(id = "0, 0", expect = ACCEPTABLE_INTERESTING, desc = "not consensus")
@Outcome(expect = ACCEPTABLE, desc = "boring")
public class TestConsensus {
int x;
int y;
private static final VarHandle X;
private static final VarHandle Y;
static {
try {
X = MethodHandles.lookup().findVarHandle(TestConsensus.class, "x", int.class);
Y = MethodHandles.lookup().findVarHandle(TestConsensus.class, "y", int.class);
} catch (Exception e) {
throw new Error(e);
}
}
@Actor
public void actor1(II_Result result) {
X.setVolatile(this, 1);
result.r1 = (int) Y.getVolatile(this);
}
@Actor
public void actor2(II_Result result) {
Y.setVolatile(this, 1);
result.r2 = (int) X.getVolatile(this);
}
}
Result:
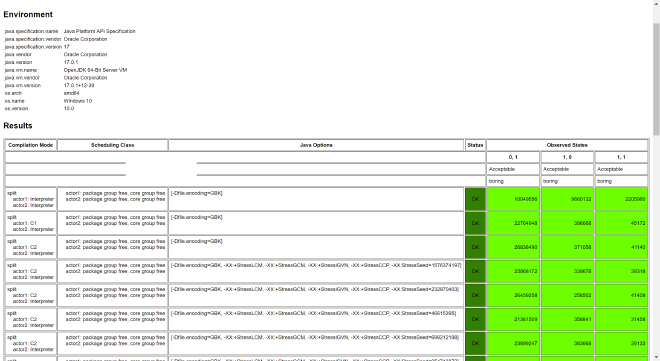
This raises another question: is this StoreLoad barrier added after Volatile Store or before Volatile Load? Let’s experiment:
First, keep Volatile Store and change Volatile Load to Plain Load:
@JCStressTest
@State
@Outcome(id = "0, 0", expect = ACCEPTABLE_INTERESTING, desc = "not consensus")
@Outcome(expect = ACCEPTABLE, desc = "boring")
public class TestConsensus {
int x;
int y;
private static final VarHandle X;
private static final VarHandle Y;
static {
try {
X = MethodHandles.lookup().findVarHandle(TestConsensus.class, "x", int.class);
Y = MethodHandles.lookup().findVarHandle(TestConsensus.class, "y", int.class);
} catch (Exception e) {
throw new Error(e);
}
}
@Actor
public void actor1(II_Result result) {
X.setVolatile(this, 1);
result.r1 = (int) Y.get(this);
}
@Actor
public void actor2(II_Result result) {
Y.setVolatile(this, 1);
result.r2 = (int) X.get(this);
}
}
Test result:
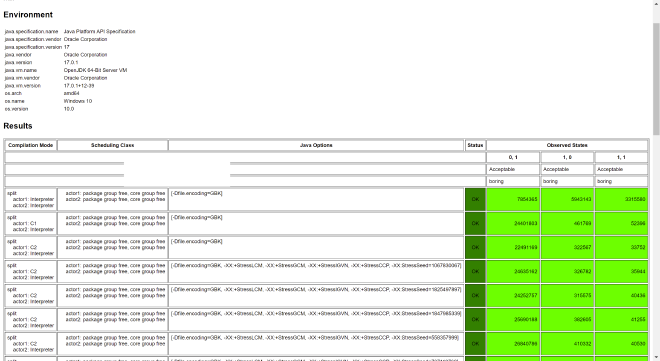
From results, Consensus is still maintained. Now let’s keep Volatile Load and change Volatile Store to Plain Store:
@JCStressTest
@State
@Outcome(id = "0, 0", expect = ACCEPTABLE_INTERESTING, desc = "not consensus")
@Outcome(expect = ACCEPTABLE, desc = "boring")
public class TestConsensus {
int x;
int y;
private static final VarHandle X;
private static final VarHandle Y;
static {
try {
X = MethodHandles.lookup().findVarHandle(TestConsensus.class, "x", int.class);
Y = MethodHandles.lookup().findVarHandle(TestConsensus.class, "y", int.class);
} catch (Exception e) {
throw new Error(e);
}
}
@Actor
public void actor1(II_Result result) {
X.set(this, 1);
result.r1 = (int) Y.getVolatile(this);
}
@Actor
public void actor2(II_Result result) {
Y.set(this, 1);
result.r2 = (int) X.getVolatile(this);
}
}
Test result:
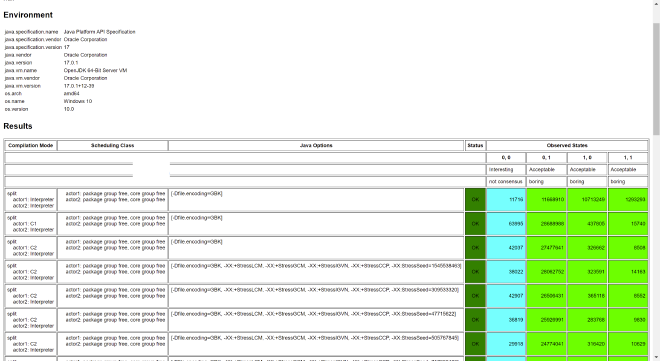
Reordering occurred again.
So we can conclude that this StoreLoad is added after Volatile writes. We’ll also see this in later JVM underlying source code analysis.
7.4 Final’s Role#
In Java, objects are created by calling class constructors, and we might initialize some field values in constructors, for example:
public class Holder {
int x;
int y;
int z;
public Holder(int i) {
this.x = i;
this.y = x + 1;
this.z = y + 1;
}
}
We can call the constructor to create an object like this:
Holder holder = new Holder(i);
Combining these steps, using pseudo-code to represent what actually executes underneath:
newOb = new Holder(); //1
newOb.x = 1; //2
newOb.y = x + 1; //3
newOb.z = y + 1; //4
Holder holder = newOb; //5
Between them, there are no memory barriers. Also, according to semantic analysis, there’s a dependency between 1 and 5, so the order of 1 and 5 cannot change. There are dependencies between 1,2,3,4, so the order of 1,2,3,4 also cannot change. Between 2,3,4 and 5, there’s no relationship - their execution order can be reordered. If 5 executes before any of 2,3,4, we might see the constructor hasn’t finished executing and x,y,z are still initial values. Let’s test:
@JCStressTest
@Outcome(id = "-1, -1, -1", expect = ACCEPTABLE, desc = "Object is not seen yet.")
@Outcome(id = "1, 2, 3", expect = ACCEPTABLE, desc = "Seen the complete object.")
@Outcome( expect = ACCEPTABLE_INTERESTING, desc = "Seeing partially constructed object.")
@State
public class TestFinal {
public static class MyObject {
int x, y, z;
public MyObject(int i) {
x = i;
y = x + 1;
z = y + 1;
}
}
MyObject o;
@Actor
public void actor1() {
o = new MyObject(1);
}
@Actor
public void actor2(III_Result r) {
MyObject o = this.o;
if (o != null) {
r.r1 = o.x;
r.r2 = o.y;
r.r3 = o.z;
} else {
r.r1 = -1;
r.r2 = -1;
r.r3 = -1;
}
}
}
On x86 platform test results, you’ll only see two results: -1, -1, -1 (representing object initialization not seen) and 1, 2, 3 (seeing object initialization without reordering), as shown below (AMD64 is an x86 implementation):
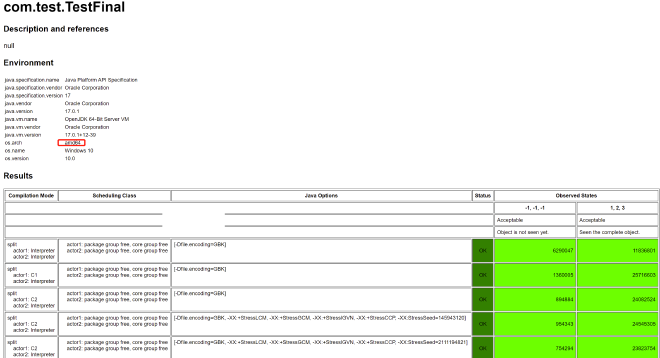
This is because, as mentioned earlier, x86 CPU is a relatively strong consistency CPU that won’t reorder here. We’ll see later which x86 non-reordering property prevents reordering here.
As before, switching to a less strongly consistent CPU (ARM), the results become more interesting, as shown below (aarch64 is an ARM implementation):

How do we guarantee seeing completed constructor execution results?
Using previous memory barrier design, we can change step 5 of pseudo-code to setRelease:
newOb = new Holder(); //1
newOb.x = 1; //2
newOb.y = x + 1; //3
newOb.z = y + 1; //4
Holder holder.setRelease(newOb); //5
We mentioned earlier that setRelease adds LoadStore and StoreStore barriers before. StoreStore barrier prevents 2,3,4 from reordering with 5, thus avoiding this problem. Let’s try:
@JCStressTest
@Outcome(id = "-1, -1, -1", expect = ACCEPTABLE, desc = "Object is not seen yet.")
@Outcome(id = "1, 2, 3", expect = ACCEPTABLE, desc = "Seen the complete object.")
@Outcome( expect = ACCEPTABLE_INTERESTING, desc = "Seeing partially constructed object.")
@State
public class TestFinal {
public static class MyObject {
int x, y, z;
public MyObject(int i) {
x = i;
y = x + 1;
z = y + 1;
}
}
MyObject o;
private static final VarHandle O;
static {
try {
O = MethodHandles.lookup().findVarHandle(TestFinal.class, "o", MyObject.class);
} catch (Exception e) {
throw new Error(e);
}
}
@Actor
public void actor1() {
O.setRelease(this, new MyObject(1));
}
@Actor
public void actor2(III_Result r) {
MyObject o = this.o;
if (o != null) {
r.r1 = o.x;
r.r2 = o.y;
r.r3 = o.z;
} else {
r.r1 = -1;
r.r2 = -1;
r.r3 = -1;
}
}
}
Testing again on the aarch64 machine, result:
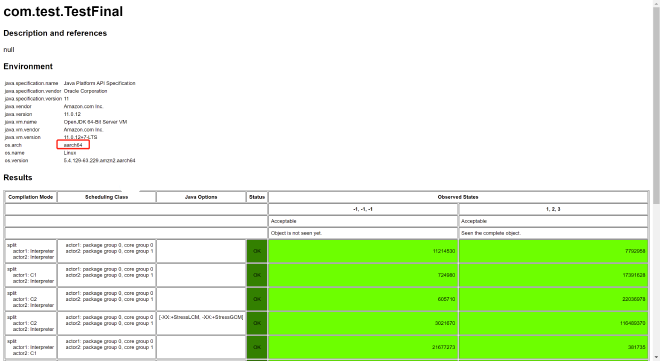
From results, we can only see either uninitialized or complete constructor execution results.
Going further, we actually only need StoreStore barrier here, which brings us to Java’s final keyword: final actually adds StoreStore barrier immediately after updates, equivalent to adding StoreStore barrier before constructor completion, ensuring that as long as we can see the object, the object’s constructor must have completed execution. Test code:
@JCStressTest
@Outcome(id = "-1, -1, -1", expect = ACCEPTABLE, desc = "Object is not seen yet.")
@Outcome(id = "1, 2, 3", expect = ACCEPTABLE, desc = "Seen the complete object.")
@Outcome(expect = ACCEPTABLE_INTERESTING, desc = "Seeing partially constructed object.")
@State
public class TestFinal {
public static class MyObject {
final int x, y, z;
public MyObject(int i) {
x = i;
y = x + 1;
z = y + 1;
}
}
MyObject o;
@Actor
public void actor1() {
this.o = new MyObject(1);
}
@Actor
public void actor2(III_Result r) {
MyObject o = this.o;
if (o != null) {
r.r1 = o.x;
r.r2 = o.y;
r.r3 = o.z;
} else {
r.r1 = -1;
r.r2 = -1;
r.r3 = -1;
}
}
}
Going even further, since 2,3,4 in pseudo-code are mutually dependent, we only need to ensure 4 executes before 5, then 2,3 will definitely execute before 5. So we only need to set z as final to add StoreStore memory barrier, rather than declaring each as final and adding multiple memory barriers:
@JCStressTest
@Outcome(id = "-1, -1, -1", expect = ACCEPTABLE, desc = "Object is not seen yet.")
@Outcome(id = "1, 2, 3", expect = ACCEPTABLE, desc = "Seen the complete object.")
@Outcome(expect = ACCEPTABLE_INTERESTING, desc = "Seeing partially constructed object.")
@State
public class TestFinal {
public static class MyObject {
int x, y;
final int z;
public MyObject(int i) {
x = i;
y = x + 1;
z = y + 1;
}
}
MyObject o;
@Actor
public void actor1() {
this.o = new MyObject(1);
}
@Actor
public void actor2(III_Result r) {
MyObject o = this.o;
if (o != null) {
r.r1 = o.x;
r.r2 = o.y;
r.r3 = o.z;
} else {
r.r1 = -1;
r.r2 = -1;
r.r3 = -1;
}
}
}
Continuing with aarch64 testing, results are still correct:
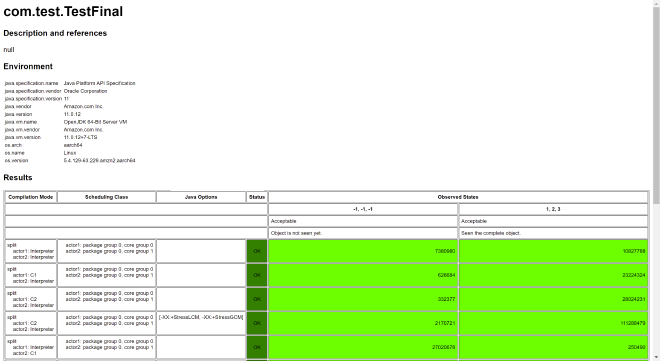
Finally, we need to note that final only adds StoreStore barrier after updates. If you expose this during constructor execution, you might still see final values uninitialized. Let’s test:
@JCStressTest
@Outcome(id = "-1, -1, -1", expect = ACCEPTABLE, desc = "Object is not seen yet.")
@Outcome(id = "1, 2, 3", expect = ACCEPTABLE, desc = "Seen the complete object.")
@Outcome(expect = ACCEPTABLE_INTERESTING, desc = "Seeing partially constructed object.")
@State
public class TestFinal {
public class MyObject {
int x, y;
final int z;
public MyObject(int i) {
o = this;
x = i;
y = x + 1;
z = y + 1;
}
}
MyObject o;
@Actor
public void actor1() {
MyObject myObject = new MyObject(1);
}
@Actor
public void actor2(III_Result r) {
MyObject o = this.o;
if (o != null) {
r.r1 = o.x;
r.r2 = o.y;
r.r3 = o.z;
} else {
r.r1 = -1;
r.r2 = -1;
r.r3 = -1;
}
}
}
This time we can see final uninitialized even on x86 machines:
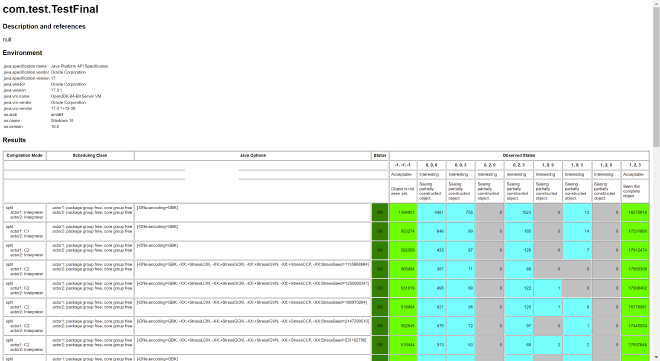
Finally, why x86 doesn’t need memory barriers to achieve this in examples, referencing the previous CPU diagram:
x86 itself doesn’t reorder Store with Store, naturally providing guarantees.
Final table:
| Java 9+ VarHandle API | Compiler Barrier | Memory Barrier | Coherence | Causality | Consensus |
|---|---|---|---|---|---|
| Plain (ordinary field access) | None | None | Not guaranteed | Not guaranteed | Not guaranteed |
| Opaque (similar to C++ volatile) | Yes | None | Guaranteed | Not guaranteed | Not guaranteed |
| Release/Acquire | Yes | Release: LoadStore + StoreStore before; Acquire: LoadLoad + LoadStore after | Guaranteed | Guaranteed | Not guaranteed |
| Volatile | Yes | Volatile write: LoadStore + StoreStore before; StoreLoad after; Volatile read: LoadLoad + LoadStore after | Guaranteed | Guaranteed | Guaranteed |
| Final | Yes | Only adds StoreStore barrier after final Store | Not guaranteed | Not guaranteed | Not guaranteed |
8. Underlying JVM Implementation Analysis#
8.1. OrderAccess Definition in JVM#
JVM has various places using memory barriers:
- Implementing Java syntax elements (volatile, final, synchronized, etc.)
- Implementing JDK APIs (VarHandle, Unsafe, Thread, etc.)
- GC-required memory barriers: considering GC multi-threading and application thread (called Mutator in GC algorithms) working methods - whether stop-the-world (STW) or concurrent
- Object reference barriers: e.g., generational GC, copying algorithm. During young generation GC, we generally copy surviving objects from one S area to another S area. If we don’t want stop-the-world during copying but want to proceed concurrently with application threads, we need memory barriers
- Maintenance barriers: e.g., partitioned GC algorithms need to maintain cross-region reference tables and usage tables for each region, like Card Table. If we want application threads and GC threads to concurrently modify access rather than stop-the-world, memory barriers are also needed
- JIT also needs memory barriers: similarly, whether application threads interpret execute code or execute JIT-optimized code also requires memory barriers.
These memory barriers need different underlying code implementations for different CPUs and operating systems. The unified interface design is:
class OrderAccess : public AllStatic {
public:
//LoadLoad barrier
static void loadload();
//StoreStore barrier
static void storestore();
//LoadStore barrier
static void loadstore();
//StoreLoad barrier
static void storeload();
//acquire barrier
static void acquire();
//release barrier
static void release();
//fence barrier
static void fence();
}
Different CPUs and operating systems have different implementations. Combined with the previous CPU reordering table:
Let’s look at linux + x86 implementation:
//Compiler barrier, actually just c++ volatile, no memory barriers
static inline void compiler_barrier() {
__asm__ volatile ("" : : : "memory");
}
//fence barrier: x86 only has StoreLoad reordering, mfence can also implement full barrier, but this instruction is considered slower than lock + addl here
//so lock + addl instruction is used here, also needs compiler_barrier to form complete fence
inline void OrderAccess::fence() {
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
compiler_barrier();
}
//x86 CPU itself doesn't reorder Load with Load, so only compiler barrier needed
inline void OrderAccess::loadload() { compiler_barrier(); }
//x86 CPU itself doesn't reorder Store with Store, so only compiler barrier needed
inline void OrderAccess::storestore() { compiler_barrier(); }
//x86 CPU itself doesn't reorder Load with Store, so only compiler barrier needed
inline void OrderAccess::loadstore() { compiler_barrier(); }
//x86 CPU can't guarantee Store with Load won't reorder, use fence to implement storeload
inline void OrderAccess::storeload() { fence(); }
//acquire equals LoadLoad + LoadStore, so only compiler barrier needed here
inline void OrderAccess::acquire() { compiler_barrier(); }
//release equals StoreStore + LoadStore, so only compiler barrier needed here
inline void OrderAccess::release() { compiler_barrier(); }
For x86, since Load with Load, Load with Store, Store with Store naturally have consistency guarantees, as long as there’s no compiler reordering, there are natural StoreStore, LoadLoad, LoadStore barriers, so we see StoreStore, LoadLoad, LoadStore barrier implementations only add compiler barriers. Also, as analyzed earlier, acquire is equivalent to adding LoadLoad, LoadStore barriers after Load, which for x86 still only needs compiler barriers. Release, as analyzed earlier, is equivalent to adding LoadStore and StoreStore before Store, which for x86 still only needs compiler barriers.
Let’s look at Linux aarch64 implementation we often use:
//These don't use specific CPU instructions but C++ standard library functions for memory barriers
//Full barrier
#define FULL_MEM_BARRIER __sync_synchronize()
//Read barrier
#define READ_MEM_BARRIER __atomic_thread_fence(__ATOMIC_ACQUIRE);
//Write barrier
#define WRITE_MEM_BARRIER __atomic_thread_fence(__ATOMIC_RELEASE);
//acquire implemented through read barrier
inline void OrderAccess::acquire() {
READ_MEM_BARRIER;
}
//release implemented through write barrier
inline void OrderAccess::release() {
WRITE_MEM_BARRIER;
}
//fence implemented through full barrier
inline void OrderAccess::fence() {
FULL_MEM_BARRIER;
}
//LoadLoad implemented through read barrier
inline void OrderAccess::loadload() { acquire(); }
//StoreStore implemented through write barrier
inline void OrderAccess::storestore() { release(); }
//LoadStore implemented through read barrier
inline void OrderAccess::loadstore() { acquire(); }
//StoreLoad implemented through full barrier
inline void OrderAccess::storeload() { fence(); }
As mentioned in the previous table, ARM CPUs have Load with Load, Load with Store, Store with Store, Store with Load all reordering. JVM for aarch64 doesn’t directly use CPU instructions but uses C++ encapsulated memory barrier implementations. C++ encapsulated barriers are very similar to our simplified CPU model memory barriers: read memory barrier (__atomic_thread_fence(__ATOMIC_ACQUIRE)), write memory barrier (__atomic_thread_fence(__ATOMIC_RELEASE)), read-write memory barrier (full memory barrier, __sync_synchronize()).
Acquire’s role is as receiving point to unpack and let everything after see package contents. Analogizing to simplified CPU model, it’s actually blocking wait for invalidate queue to be completely processed ensuring CPU cache has no dirty data. Release’s role is as launch point to package previous updates and send out. Analogizing to simplified CPU model, it’s actually blocking wait for store buffer to completely flush into CPU cache. So acquire and release use read memory barrier and write memory barrier respectively.
LoadLoad ensures first Load before second, which is actually adding read memory barrier after first Load, blocking wait for invalidate queue to be completely processed. LoadStore similarly ensures first Load before second Store - as long as invalidate queue is processed, there’s no corresponding dirty data in current CPU, no need to wait for current CPU’s store buffer to also clear.
StoreStore ensures first Store before second, which is actually adding read memory barrier after first write, blocking wait for store buffer to completely flush into CPU cache. For StoreLoad, it’s special - since second Load needs to see Store’s latest value, updates can’t just reach store buffer, and expiration can’t exist in unprocessed invalidate queue, so read-write memory barrier (full barrier) is needed.
8.2. Memory Barrier Source Code for volatile and final#
Let’s look at volatile memory barrier insertion related code, using ARM as example. We can actually trace iload bytecode to see what happens if loading volatile or final keyword modified fields, and istore to see what happens if storing volatile or final keyword modified fields.
For field access, JVM also has fast path and slow path - we’ll only look at fast path code:
Corresponding source code:
void TemplateTable::fast_accessfield(TosState state) {
//Omit code for actual Load execution
//Check if volatile modified
Label notVolatile;
__ tbz(Rflags, ConstantPoolCacheEntry::is_volatile_shift, notVolatile);
//If so, add LoadLoad + LoadStore memory barriers
volatile_barrier(MacroAssembler::Membar_mask_bits(MacroAssembler::LoadLoad | MacroAssembler::LoadStore), Rtemp);
__ bind(notVolatile);
}
void TemplateTable::fast_storefield(TosState state) {
//Omit irrelevant code
//Check if volatile modified
Label notVolatile;
__ tbz(Rflags, ConstantPoolCacheEntry::is_volatile_shift, notVolatile);
//If so, add StoreStore + LoadStore memory barriers
volatile_barrier(MacroAssembler::Membar_mask_bits(MacroAssembler::StoreStore | MacroAssembler::LoadStore), Rtemp);
__ bind(notVolatile);
//Omit code for actual Store execution
Label notVolatile2;
Label skipMembar;
//Check if volatile modified or final modified
__ tst(Rflags, 1 << ConstantPoolCacheEntry::is_volatile_shift |
1 << ConstantPoolCacheEntry::is_final_shift);
__ b(skipMembar, eq);
__ tbz(Rflags, ConstantPoolCacheEntry::is_volatile_shift, notVolatile2);
//If volatile, add StoreLoad memory barrier
volatile_barrier(MacroAssembler::StoreLoad, Rtemp);
__ b(skipMembar);
//If final, add StoreStore memory barrier
__ bind(notVolatile2);
volatile_barrier(MacroAssembler::StoreStore, Rtemp);
__ bind(skipMembar);
}
This completes our comprehensive journey through Java 9+ Memory Model, from basic concepts to practical implementation details. Understanding these concepts and their underlying mechanisms will help you write more robust concurrent Java applications.