
Choosing Java Agentic AI Frameworks: Three Orchestration Paths for One Business Scenario#
Shipping agentic applications on the JVM is rarely blocked by “can we call an LLM?” The harder question is who decides the next step: Java code with a fixed flow, or the model choosing tools and sub-agents at runtime. Spring AI, LangChain4j, and Embabel sit at three abstraction levels—low-level primitives, declarative agent composition, and goal-driven planning.
The reference scenario is Nutrition Planner: fetch user profile and seasonal ingredients in parallel, generate a weekly meal plan that respects allergies and calorie constraints, then run an Evaluator-Optimizer loop for nutritional validation. All three frameworks implement the same business semantics, but orchestration responsibility lands at different layers—hand-written Java concurrency, AgenticServices builders, or GOAP automatic replanning. This article maps mechanism differences and engineering trade-offs; capability matrices, version timelines, and quantitative token estimates are called out separately where they have not been independently benchmarked. Readers can clone ai-nutrition-planner, run all three modules locally, and then choose.
Agentic Evolution and Workflow Trade-offs#
Why: The typical LLM application path runs: Prompt Engineering → RAG grounding → Tool Calling → Multimodal → Agentic Systems. RAG and tool calling answer “the model can read data and call functions”; agentic systems go further by handing orchestration decisions to the model—multi-agent collaboration, memory, planning, and MCP interconnect. For production systems, the key question is which steps must stay predictable and testable, and which are worth trading for model flexibility at the cost of latency and spend.
Mechanism / constraints: Anthropic’s engineering post splits orchestration into Workflows (predefined code paths) and Agents (the model directs dynamically). Workflows are predictable, easier to maintain, and usually lower in latency and token cost; pure agents fit open-ended tasks but add multi-round reasoning expense, and a single bad step can cascade. Anthropic advises “start with the simplest approach and add complexity only when needed.” The source says “workflows offer predictability… agents are the better option when flexibility… is needed”—“enterprises should prefer workflows” is common engineering shorthand, not an official hard rule. The slides summarize agentic capability blocks as Orchestration / Memory / Planning / MCP—this is the speakers’ synthesis and does not map word-for-word to Anthropic’s taxonomy.

Agentic AI Systems blocks list Orchestration, Memory, Planning, and MCP—marking the shift from single-turn generation to end-to-end automation.

Workflows vs. pure agents: slide conclusion “Use workflows for predictability,” aligned with Anthropic’s narrative.
How: All three Nutrition Planner implementations lean Workflow rather than pure agent—parallel phases are fixed in code, validation uses an Evaluator-Optimizer pattern instead of letting the model freely plan the full pipeline. If you can enumerate steps during requirements review, prefer a workflow; consider a pure agent only when task decomposition itself is unpredictable (e.g., an open-ended research assistant).
Common pitfalls: Equating “we use an LLM” with “we built an agent”; defaulting to pure agents in compliance or audit-heavy settings without guardrails, observability, and human-in-the-loop points; forcing Routing into an inflexible workflow without maintaining classifier accuracy.
Five Workflow Patterns as an Architecture Blueprint#
Why: A single prompt that generates a weekly meal plan struggles to reliably satisfy structured constraints like allergies and calories; the business needs to map onto a step graph that can be coded and tested.
Mechanism / constraints: Anthropic lists five patterns—Prompt Chaining, Parallelization, Routing, Orchestrator-Workers, and Evaluator-Optimizer. Parallelization has Sectioning (parallel subtasks) and Voting (multi-path voting) variants; Evaluator-Optimizer is defined as “one LLM generates, another evaluates and feeds back, looping until criteria are met.”
Nutrition Planner maps to: Parallelization (fetchUserProfile and fetchSeasonalIngredients are independent and can run in parallel) → plan generation in a Prompt Chaining style → Evaluator-Optimizer (NutritionGuard evaluates + Reviser revises). User allergies, sodium caps, and similar constraints live on the Evaluator side rather than expecting the Generator to remember every rule in one shot. Spring AI ships StructuredOutputValidationAdvisor for JSON schema retries—semantically close to Evaluator-Optimizer, but Anthropic’s post does not establish a one-to-one API mapping.

Workflow Patterns for Agentic Systems: Evaluator-Optimizer shows a Generator ↔ Evaluator feedback loop; footer links to Anthropic’s engineering post.

How: Regardless of framework, sketch the business using these patterns first, then pick matching primitives—do not start from “what does the framework offer?” and force-fit the domain.
Common pitfalls: Conflating Orchestrator-Workers with Evaluator-Optimizer—the former dynamically decomposes subtasks from a central LLM; the latter is a fixed generate-evaluate pair.
MCP and A2A: Two Axes of Interoperability#
Why: After tool calling became common, every agent wrapping its own GitHub, Jira, and DB connectors does not scale; the Java ecosystem needs standard protocols to reduce integration fragmentation.
Mechanism / constraints: The MCP specification is an open standard for connecting AI applications to external data sources and tools; the A2A protocol (maintained by The Linux Foundation) describes multi-agent discovery, delegation, and collaboration—agents exposed as agents, not only wrapped as tools. The Nutrition Planner demo implements an MCP server, not A2A interoperability (the sample repo has no A2A dependencies).
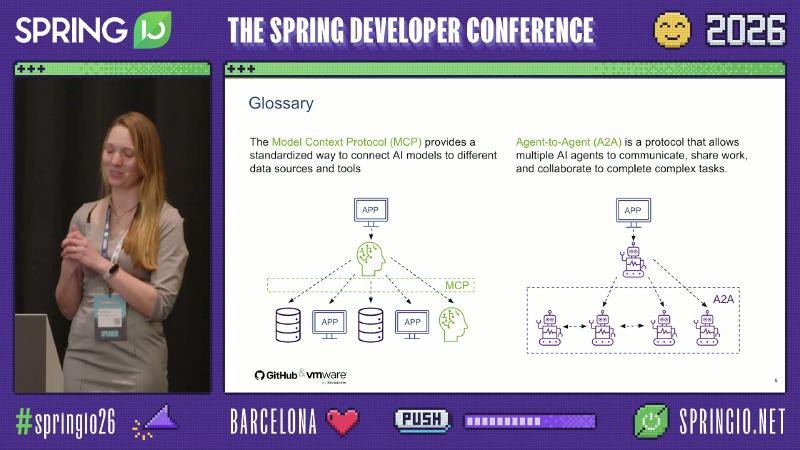
Glossary: MCP connects the AI model to DB/APP; A2A shows multiple agents collaborating bidirectionally.
How: MCP solves “model ↔ tools/data”; A2A solves “agent ↔ agent.” The Spring AI module exposes createNutritionPlan as an MCP tool via @McpTool and reads the current user from SecurityContextHolder—showing MCP and Spring Security can share the same stack. Evaluate client and server separately when choosing: LangChain4j has an MCP client (Streamable HTTP, stdio) and a community stdio server, while Spring AI’s spring-ai-starter-mcp-server-webmvc and Embabel’s embabel-agent-starter-mcpserver HTTP starters are not equally mature—you cannot simplify that to “does not support MCP.”
Common pitfalls: Treating MCP server and MCP client as the same thing; reading “No HTTP Server” in a matrix without separating transport layer from first-class starter support; assuming all three frameworks are production-ready for agent-to-agent interoperability when the demo never covered A2A.
Spring AI: Advisor Chains and Hand-Written Workflows#
Why: The Spring team has invested heavily in Spring AI and Boot integration; if you are already on the Spring stack, you need to know the framework gives primitives, not an out-of-the-box workflow engine.
Mechanism / constraints: Spring AI provides ChatClient, CallAdvisor, MCP starters, and more. As of 1.1.x, there is no GA abstraction named Workflow—Workflow.parallel in the sample repo is a project-local Supplier concurrency helper (demo version 1.1.4), not a framework API.
Evaluator-Optimizer is implemented via a custom ValidationRetryAdvisor: in adviseCall, call chain.nextCall(request) first, convert the response to WeeklyPlan with BeanOutputConverter, then run the domain validator; on failure, write validation feedback back into the user message and retry with chain.copy(this).nextCall(request). Source uses a for loop with maxRetries=3—semantically equivalent to the slide’s while(true) demo, but a different implementation. If validation only needs JSON schema enforcement, use the built-in StructuredOutputValidationAdvisor instead of reimplementing ValidationRetryAdvisor.
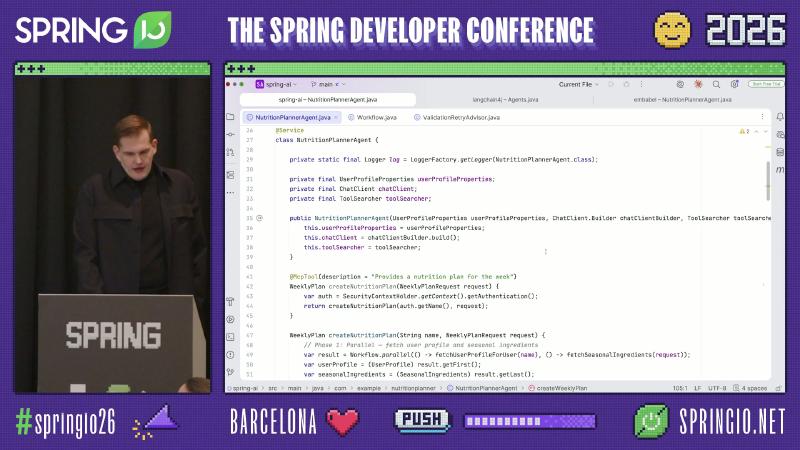
Spring AI module: Phase 1 comments and Workflow.parallel fetching UserProfile and SeasonalIngredients in parallel.
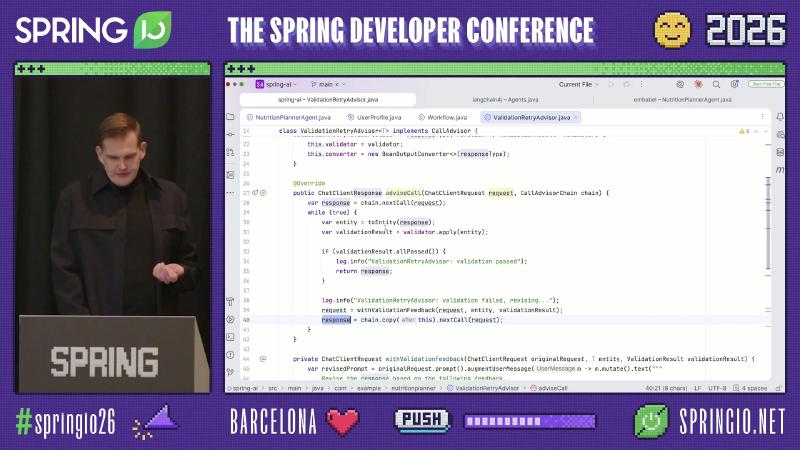
ValidationRetryAdvisor implements CallAdvisor, revising and retrying when validation fails.
How (minimal server-side snippet):
WeeklyPlan createNutritionPlan(String name, WeeklyPlanRequest request) {
var result = Workflow.parallel(
() -> fetchUserProfileForUser(name),
() -> fetchSeasonalIngredients(request));
var advisor = new ValidationRetryAdvisor<>(WeeklyPlan.class,
plan -> validateWeeklyPlan(plan, profile));
return chatClient.prompt()
.system(Personas.RECIPE_CURATOR)
.user(u -> u.text(PROMPT).param("days", request.days()))
.advisors(advisor)
.call().entity(WeeklyPlan.class);
}
The demo also uses the community ToolSearchToolCallAdvisor for on-demand tool exposure—not Spring AI GA core; whether it lands in Spring AI 2.0 (milestone due 2026-06-11) requires tracking release notes.
Common pitfalls: Assuming Workflow.parallel comes from Spring AI; ignoring the maxRetries cap; misordering the advisor chain—validation advisors belong on the final call() path, and recursive depth from copy(after: this) must be observable; treating community ToolSearchToolCallAdvisor as official Spring GA.
LangChain4j: Experimental AgenticServices#
Why: If you want builders and annotations for sub-agents, sequences, and loops—less hand-written concurrency and retry—langchain4j-agentic offers a higher-level API, but the module is marked experimental; pin versions.
Mechanism / constraints: Core entry points are AgenticServices.agentBuilder / sequenceBuilder / loopBuilder / parallelBuilder. Sub-agents are declared with @Agent interfaces and @V parameters; e.g., SeasonalIngredientAgent writes results to AgenticScope via outputKey = "seasonalIngredients" for downstream agents. Loops need maxIterations and exitCondition; official docs evaluate exit after sub-agent calls by default—without a defined exit condition, early termination may never happen (speaker experience). The sample repo (langchain4j 1.13.0) supports both builder style and @SequenceAgent / @LoopAgent / @ExitCondition annotations, behavior-equivalent to the slide’s builder syntax.
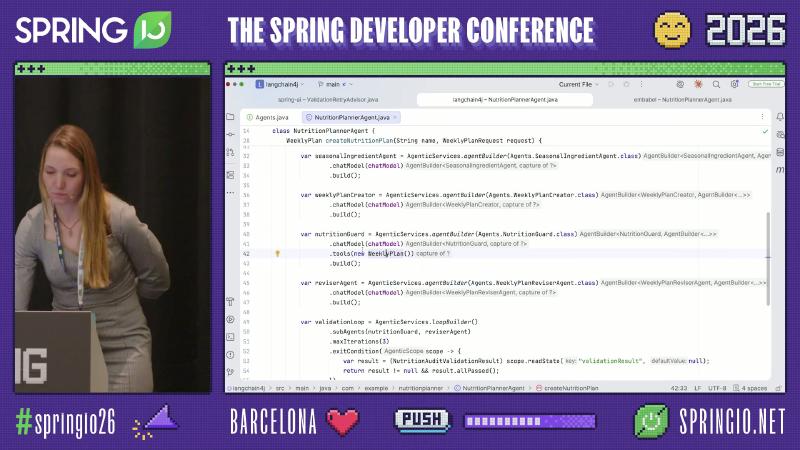
LangChain4j: AgenticServices.loopBuilder().subAgents(nutritionGuard, reviserAgent).maxIterations(3).
How:
var validationLoop = AgenticServices.loopBuilder()
.subAgents(nutritionGuard, reviserAgent)
.maxIterations(3)
.exitCondition(scope -> {
var r = (NutritionAuditValidationResult)
scope.readState("validationResult", null);
return r != null && r.allPassed();
}).build();
var planner = AgenticServices.sequenceBuilder(Agents.NutritionPlanner.class)
.subAgents(seasonalAgent, weeklyPlanCreator, validationLoop)
.outputKey("weeklyPlan")
.build();
LangChain4j documentation maps Anthropic’s five patterns to sequential / parallel / routing / planner / loop workflows—coverage is verifiable at the documentation layer. Compared with Spring AI, LangChain4j pulls parallel and loop logic out of application code into framework builders, at the cost of experimental API stability and Spring-level starter documentation depth.
Common pitfalls: Treating experimental as production GA; shipping without evaluating behavior differences between testExitAtLoopEnd = true and exit checks after every sub-call; forgetting to attach the WeeklyPlan tool object to NutritionGuard inside the loop, so the Evaluator cannot compute nutrition.
Embabel: GOAP Planning and Stage State Machines#
Why: Hard-coded call order grows brittle as domain types multiply; Embabel (led by Rod Johnson, not GA as of the demo) drives orchestration on the JVM with @Action plus a domain type graph, while the LLM handles single-step reasoning only.
Mechanism / constraints: Embabel’s README says “From the creator of Spring”; the demo depends on com.embabel.agent 0.3.5 and the guide still carries SNAPSHOT tags—treat as preview before production. Default planning is GOAP (Goal Oriented Action Planning); source AStarGoapPlanner notes “using the A* algorithm”—public docs say GOAP, the talk emphasizes A*; the precise wording is “GOAP planning (A implementation).”* Embabel also supports Utility, Hybrid, Supervisor, and other planners, but the demo uses default GOAP.
After each @Action completes, the framework replans (OODA loop): e.g., createWeeklyPlan needs WeeklyPlanRequest, UserProfile, and SeasonalIngredients ready—the planner arranges fetch order instead of the developer hard-coding a call list. @Action preconditions are expressed through domain types in method signatures; Ai.withLlm(LlmOptions.withAutoLlm()) wraps single-step structured output. GOAP planning failure when dependencies are missing—specific exceptions and fallback strategies—are not fully validated in the public demo.
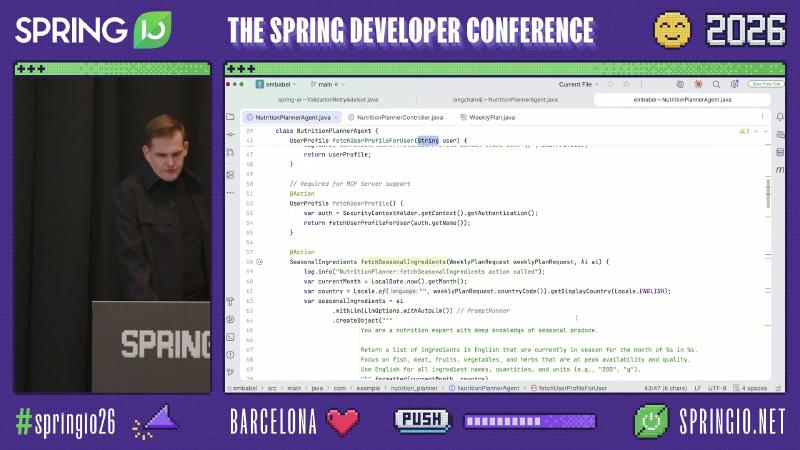
Embabel: @Action method fetchSeasonalIngredients(WeeklyPlanRequest, Ai ai); comment “Required for MCP Server support.”
The Evaluator-Optimizer branch is encoded as a Stage state machine: NutritionAudit record implements Stage; validate returns Done or ReviseWeeklyPlan; the framework schedules @Action(canRerun = true) reruns—more declarative than Spring AI’s hand-written while-loop.
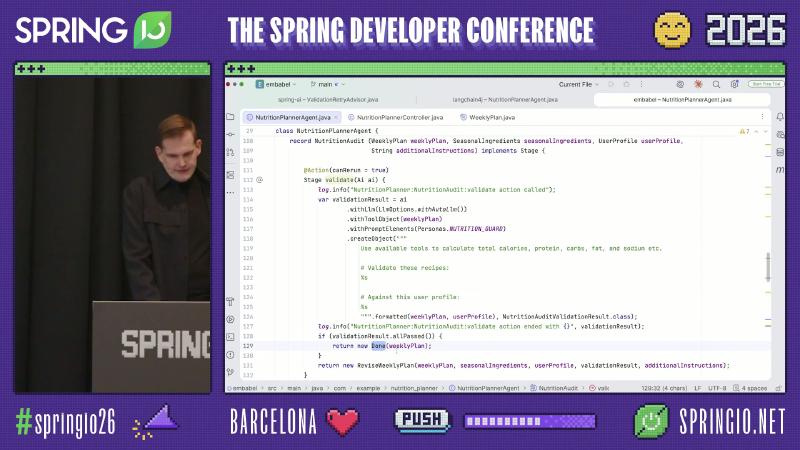
NutritionAudit validate: “Use available tools to calculate total calories, protein, carbs, fat, and sodium.”
How:
@Action
SeasonalIngredients fetchSeasonalIngredients(WeeklyPlanRequest req, Ai ai) {
return ai.withLlm(LlmOptions.withAutoLlm())
.createObject(SEASONAL_PROMPT.formatted(month, country),
SeasonalIngredients.class);
}
record NutritionAudit(...) implements Stage {
@Action(canRerun = true)
Stage validate(Ai ai) {
var result = ai.withLlm(LlmOptions.withAutoLlm())
.withToolObject(weeklyPlan)
.createObject(..., NutritionAuditValidationResult.class);
return result.allPassed()
? new Done(weeklyPlan)
: new ReviseWeeklyPlan(...);
}
}
The REST entry starts via AgentInvocation (0.3.5 API: AgentInvocation.builder(agentPlatform).build(WeeklyPlan.class) + invoke(inputs)), sharing the same agent capabilities as the MCP server.
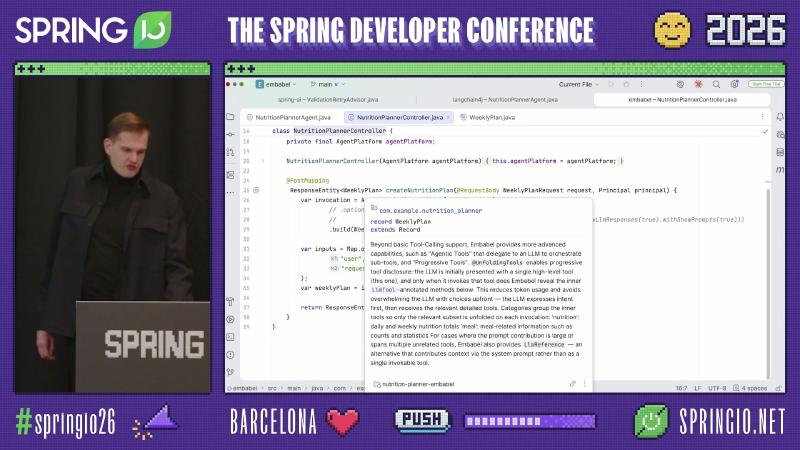
NutritionPlannerController injects AgentPlatform; tooltip explains @UnfoldingTools progressive tool disclosure.
Common pitfalls: Treating A* as a separate planner toggle alongside GOAP rather than the implementation inside GOAP; betting production SLAs on a non-GA version; assuming exception types and fallback behavior on planning failure are proven in the public demo.
Tool Exposure Strategy Under Token Economics#
Why: Anthropic’s advanced tool use direction notes that large tool schemas consume context—“100 tools × metadata” is unsustainable under per-token billing (the quantitative model is industry consensus; there is no public benchmark comparing the three frameworks).
Mechanism / constraints: Mitigations include progressive disclosure, tool search, and category filtering. In nutrition validation, WeeklyPlan may expose a dozen tools for per-day stats, per-meal counts, sodium/protein totals, and more—registering everything at once squeezes tool schema into context that could hold recipe content.
Embabel @UnfoldingTools initially exposes one high-level tool; the LLM states intent first (e.g., category 'nutrition'), then the framework unfolds the matching @LlmTool subset; LlmReference injects large context into the system prompt instead of as a callable tool. The Spring AI demo uses community ToolSearchToolCallAdvisor + ToolSearcher for similar on-demand exposure—aligned with Anthropic advanced tool use, but implemented in different packages.
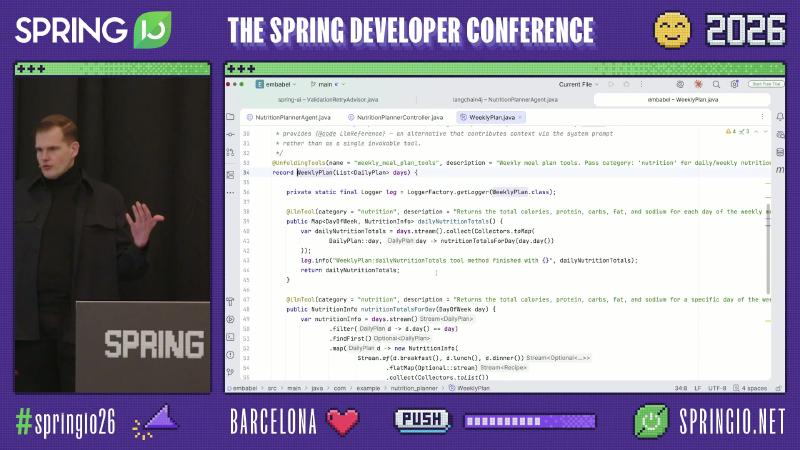
@UnfoldingTools(name = "weekly_meal_plan_tools"—pass category nutrition to unfold @LlmTool methods.
How:
@UnfoldingTools(name = "weekly_meal_plan_tools",
description = "Pass category: 'nutrition' for daily/weekly totals")
record WeeklyPlan(List<DailyPlan> days) {
@LlmTool(category = "nutrition")
Map<DayOfWeek, NutritionInfo> dailyNutritionTotals() { ... }
}
Common pitfalls: Counting prompt length only and ignoring tool-definition tokens; exposing every helper as @LlmTool without layering; Spring AI tool search GA timing is not confirmed in official docs (as of 2026-06-10); assuming progressive disclosure always saves tokens versus full registration without measurement (in very short dialogs, the opposite can happen).
Three-Framework Comparison: Abstraction Level and Ecosystem Fit#
Why: Framework choice is fundamentally a trade-off between how much orchestration you will hand-write and how much framework magic and version risk you accept.
Mechanism / constraints: The table below synthesizes the GitHub sample repo and official docs; red/yellow/green capability matrices are subjective snapshots from the talk (subtitles also note current state), not independent benchmarks.
| Dimension | Spring AI | LangChain4j | Embabel |
|---|---|---|---|
| Abstraction level | Low (ChatClient / Advisor) | Medium (AgenticServices) | High (Stage / GOAP) |
| Workflow out of the box | Hand-written + built-in validation advisor | agentic module (experimental) | Built-in patterns |
| Spring Boot starter | First-class | Demo includes starter; doc depth varies over time | Built on Spring AI ecosystem |
| MCP HTTP server | spring-ai-starter-mcp-server-webmvc | Community stdio server primary | embabel-agent-starter-mcpserver |
| GA status | Broadcom enterprise track | Community + Red Hat/IBM contributions | Not GA (0.3.x) |

Comparing Agentic AI Frameworks Capabilities matrix: LangChain4j MCP marked No HTTP Server, Embabel all green—read alongside the MCP nuance above.

How (decision heuristics, not dogma):
- Predictable pipeline + existing Spring investment: Spring AI +
StructuredOutputValidationAdvisor, with orchestration written explicitly; lowest migration cost when the team already knows@ServiceandChatClient.Builderinjection. - Fast sub-agent + loop prototyping: LangChain4j agentic—pin versions, accept experimental churn; fits PoC or internal tools; budget upgrade windows for API breaking changes.
- Declarative Stage + goal planning: Embabel is expressive and domain types serve as documentation; production requires accepting non-GA status and replan uncertainty, and understanding that GOAP replanning each step can add planning overhead.
- MCP server needs first-class HTTP integration: Verify starters and transport types line by line—do not rely on matrix colors alone.
- Observability and testing: All three demos lean workflow; unit tests should cover validators and parallel phases; pure-agent paths need heavier LLM-as-judge integration tests.
If the question is simply “which is best”—there is no universal answer. Spring AI wins on ecosystem and control; LangChain4j wins on agentic module out-of-the-boxness; Embabel wins on pattern expression and tool disclosure, but version and GA status are hard constraints.
Common pitfalls: Using one conference matrix for long-term architecture; treating LangChain4j’s “~80% of users use Spring” as publicly verifiable data; conflating Spring AI 2.0 / Boot 4 talk dates (“May 2026”) with GitHub milestones (2.0.0 due 2026-06-11, Boot 4.1.0 due 2026-06-10); seeing Embabel all-green in the matrix while ignoring “non-GA + higher abstraction = less runtime controllability.”
References and Further Reading#
- Anthropic — Building effective agents (Workflows vs. Agents, five patterns)
- Anthropic — Advanced tool use (tool search / disclosure direction)
- Model Context Protocol official documentation
- A2A protocol — What is A2A?
- Spring AI reference documentation
- Spring AI — Advisors API
- Spring AI — Recursive Advisors (StructuredOutputValidationAdvisor)
- Spring AI 2.0.0 Milestone
- LangChain4j — Agents and Agentic AI (experimental)
- LangChain4j — MCP client tutorial
- LangChain4j — MCP stdio server
- Embabel Agent — README (GOAP, OODA replan)
- Embabel — Choosing a Planner
- AStarGoapPlanner source (A* inside GOAP)
- Nutrition Planner three-framework comparison sample repo


